Harder, Better, Faster, Stronger... Earlier!

Our Quarkus vs Spring CRUD benchmark shows Quarkus delivering roughly 2x Spring’s throughput on a REST/CRUD workload backed by PostgreSQL. The latest public results confirm this.
But throughput is an average over a measurement window. It doesn’t tell you how long the application took to get there. This post looks at the dimension averages hide: time to peak performance.
The benchmark runs on our RHEL 9.6 performance lab with JDK 25, 4 pinned cores per application, and 100 concurrent HTTP connections. The workload is CPU-bound by design, fully utilizing the 4 cores during load. Each run consists of a 2-minute warmup at full load, a 30-second cooldown, and a 30-second load test where throughput is measured.
The warmup curve
Hyperfoil records per-second throughput during each phase. Here is the warmup curve for the two baseline configurations, Quarkus and Spring, both with platform threads:
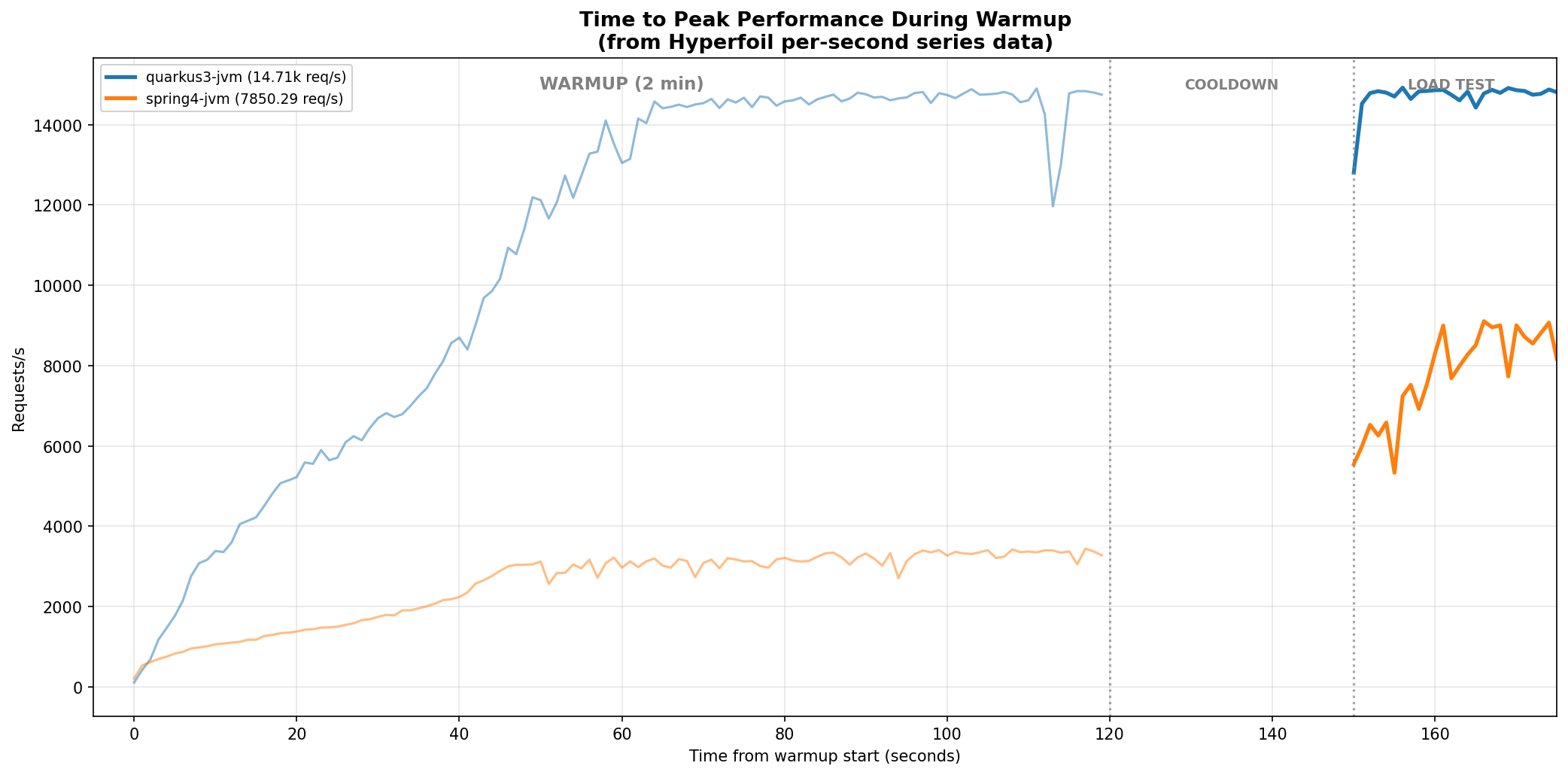
Quarkus reaches ~14,700 req/s within 60 seconds. Spring plateaus at ~3,300 req/s during warmup, then jumps to ~7,800 during the load test after the 30-second cooldown gives the compiler time to catch up.
The shape matters. Quarkus’s curve has a steep initial ramp and plateaus early. Spring plateaus at less than a quarter of Quarkus’s throughput during warmup, and only recovers after the cooldown period.
Why is Spring slower to warm up?
The HotSpot JVM uses tiered compilation: code starts in the interpreter, gets compiled by C1, and eventually by C2 which produces the fastest native code. C2 runs on dedicated background threads. If those threads can’t get CPU time, the application stays on slower code longer.
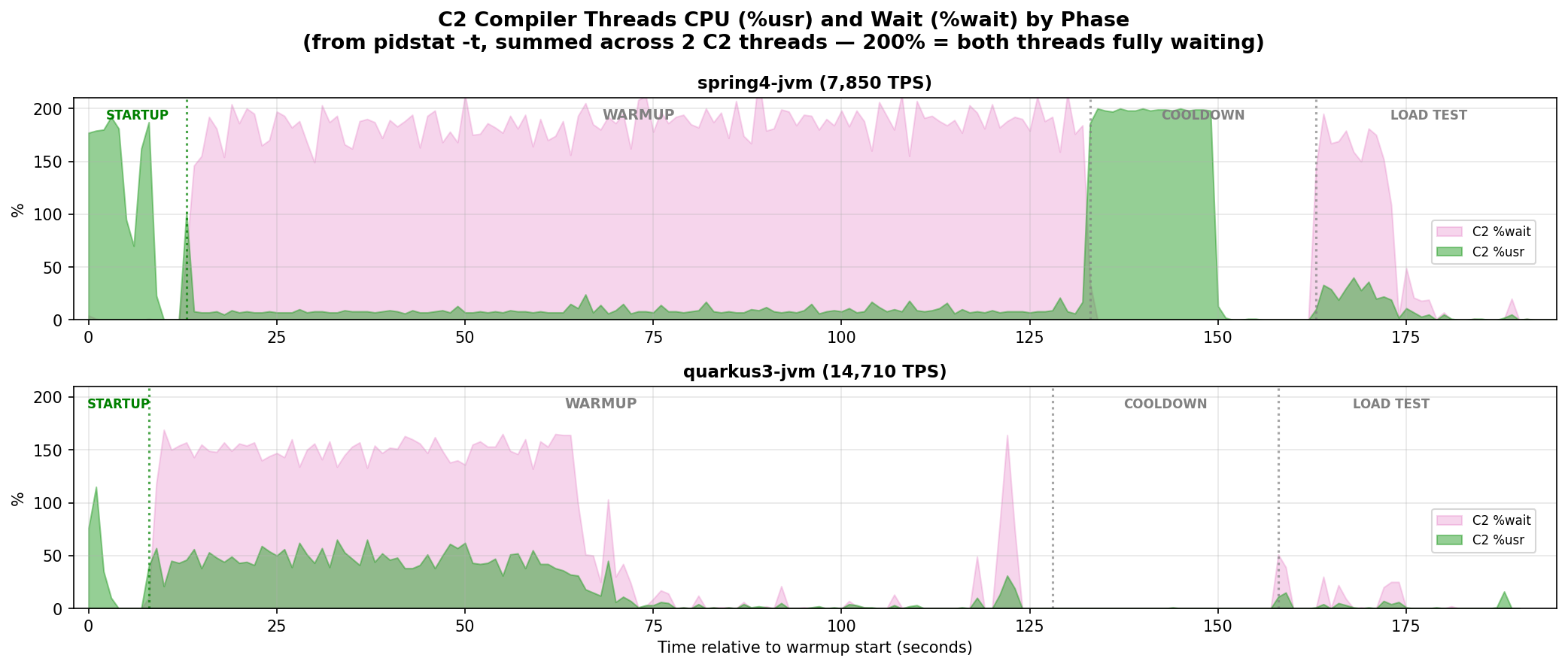
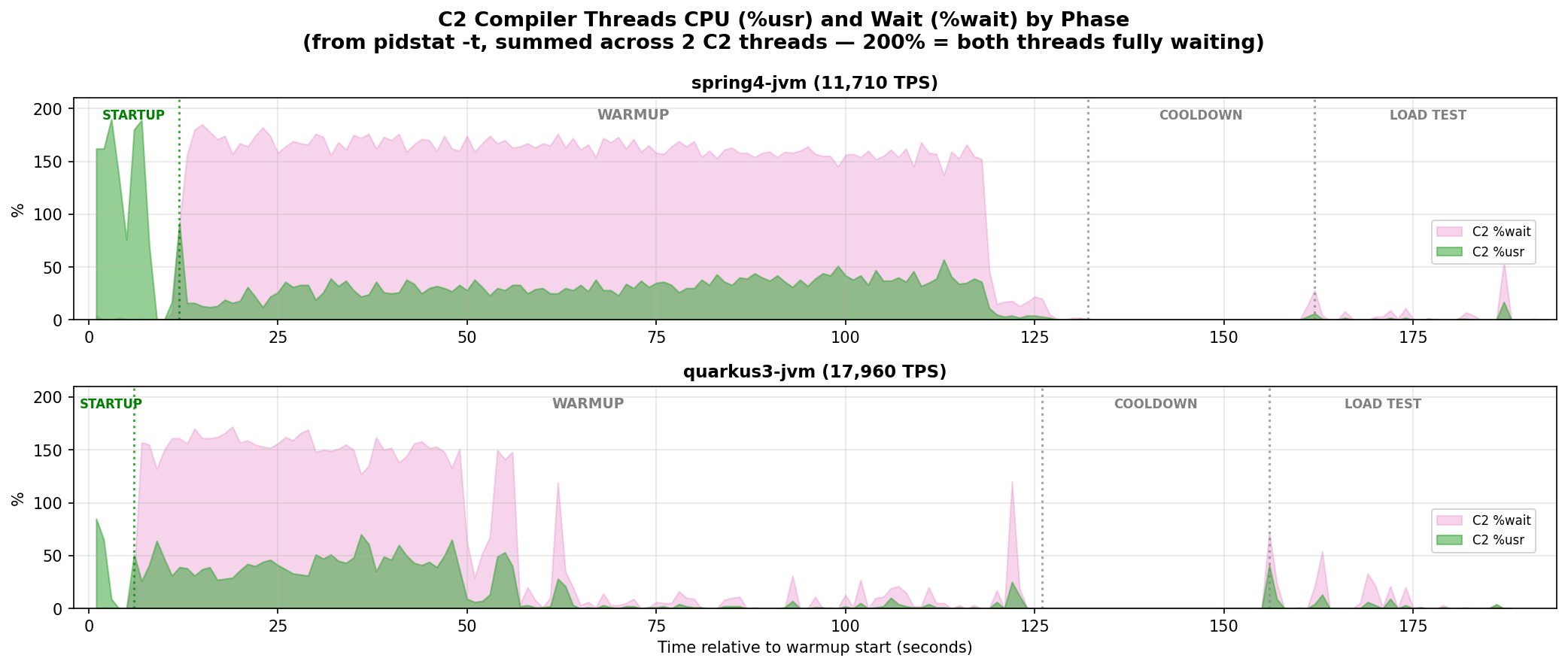
pidstat with per-thread reporting (-t) shows %wait: the percentage of time a thread spends in the run queue, ready to execute but waiting for a CPU. This is collected as part of our active benchmarking practice.
|
The JVM runs 2 C2 compiler threads on this configuration. The chart sums both threads: 200% wait means both are fully waiting for a CPU. Green is CPU time doing actual compilation work; pink is time spent in the run queue, ready to run but waiting for a CPU. |
During startup (green region, before any request arrives), both frameworks show C2 running freely: green with no pink. Spring’s C2 threads are at ~200% usr (both maxed out), reflecting more framework code to compile at boot. Quarkus’s C2 threads peak at ~80% usr, less startup compilation work. Spring’s startup also takes longer (~13 seconds vs ~8 for Quarkus; the public benchmark results show Quarkus starts in roughly half the time).
Once the warmup load hits, the picture changes.
spring4-jvm (top panel): the C2 threads are immediately overwhelmed. The pink band fills the warmup phase, with the two threads collectively spending 140-180% of their time waiting. The compiler can barely run for the whole duration of the warmup.
quarkus3-jvm (bottom panel): C2 threads are also contended during the first half of warmup (100-150% summed wait). But C2 activity drops to near zero by the second half. The compiler finishes its work within the first ~60 seconds.
Both are starved during warmup. The difference is recovery. Quarkus needs 41% fewer total compilations to reach peak (~12,500 vs ~17,600 for Spring, from JFR’s jdk.CompilerStatistics): a leaner framework means less work for the compiler.
Quarkus is also leaner at runtime. Spring Boot’s Tomcat creates a platform thread per HTTP connection. With 100 connections, pidstat shows ~130 threads with %CPU > 0 during warmup. Quarkus shows ~47. pidstat also reports two types of context switches: voluntary (the thread yields the CPU on its own, typically because it starts waiting for I/O) and involuntary (the scheduler forcibly preempts the thread because its time slice expired). Averaged per worker thread across the warmup:
| Avg voluntary cswch/s | Avg involuntary cswch/s | Ratio nvol/vol | |
|---|---|---|---|
spring4-jvm |
105 |
864 |
8.3 |
quarkus3-jvm |
502 |
43 |
0.1 |
Spring worker threads are involuntarily preempted 20x more than Quarkus threads. Quarkus threads yield the CPU voluntarily 4x more: they complete request work faster and return to I/O wait, leaving scheduling gaps for the C2 compiler.
Starvation also degrades code quality. When the C2 queue grows too large, HotSpot’s compilation policy kicks in a backpressure mechanism: it skips tier 3 (C1 with full profiling) and compiles methods at tier 2 (C1 without full profiling) instead, reducing the load on C2. When the queue pressure drops, methods get promoted from tier 2 to tier 3 and eventually to tier 4 (C2). For spring4-jvm, JFR execution samples show this directly: during warmup, C1-compiled code dominates at ~60% of leaf frames while C2-inlined code stays at ~30%. The C2 queue peaks at over 3,000 pending methods and stays there for the entire warmup. After the 30-second cooldown gives C2 the CPU it needs, the picture flips: C2-inlined code jumps to ~80% and C1 drops to ~20%. The throughput jump after cooldown is the C2-compiled code finally running.
Virtual threads change the equation
Virtual threads multiplex onto a small number of carrier threads. With 100 HTTP connections, only ~4 carriers are on-CPU instead of 100+ platform threads. Adding virtual threads to both frameworks:
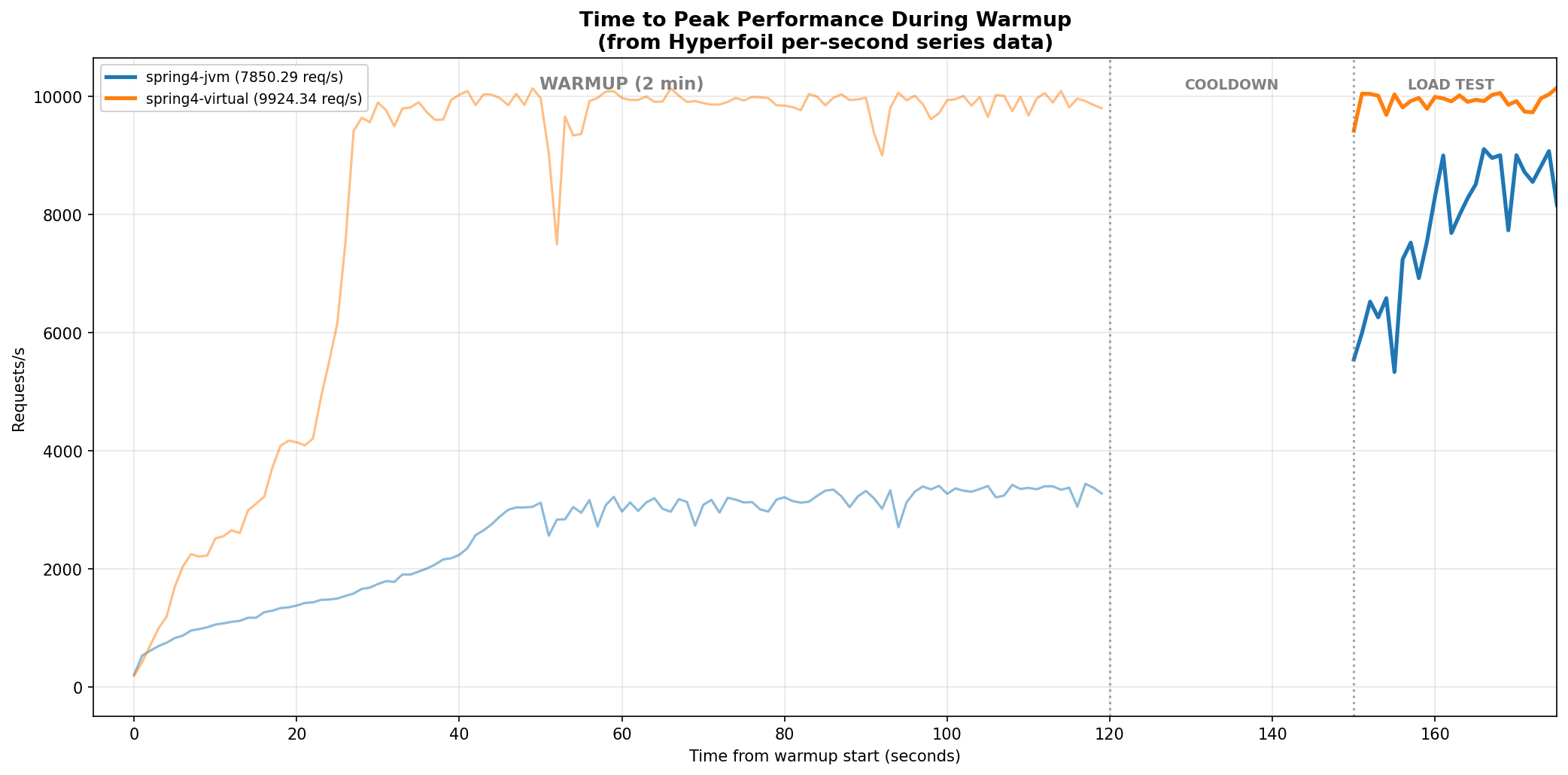
Spring with virtual threads reaches ~9,900 req/s and warms up within 30 seconds. With platform threads, Spring is still at ~3,300 req/s at the 30-second mark, and is still climbing during the load test, never reaching a stable peak within the entire benchmark window.
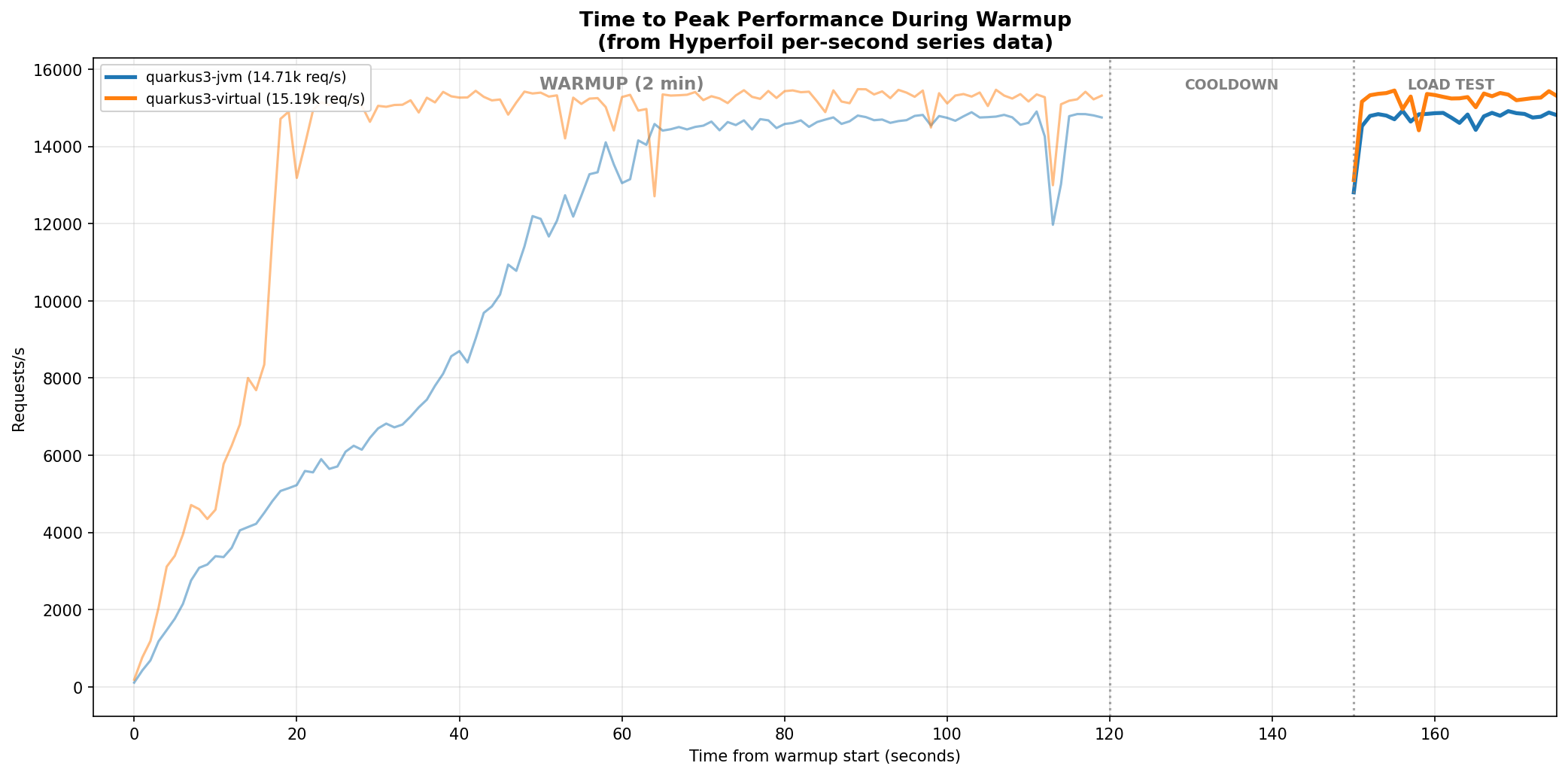
Quarkus with virtual threads reaches peak in ~15 seconds instead of ~60 seconds, but both converge to ~15,000 req/s. The benefit is warmup speed, not peak throughput.
Fewer threads competing for 4 cores means the C2 compiler threads get more CPU time during warmup.
What about Leyden?
Project Leyden in JDK 25 caches class loading, linking, and method profiling data in an AOT cache (JEP 483, JEP 514, JEP 515). AOT Code Compilation (caching the actual C2-compiled native code) is not yet in JDK 25 and is available on the Leyden premain branch for future releases.
The AOT cache accelerates startup: Spring starts in 6.4s with Leyden vs 9.3s without. But warmup tells a different story.
Our benchmark follows the official Spring Boot AOT cache documentation, which uses -Dspring.context.exit=onRefresh for the training run: class loading and context initialization only, no HTTP traffic.
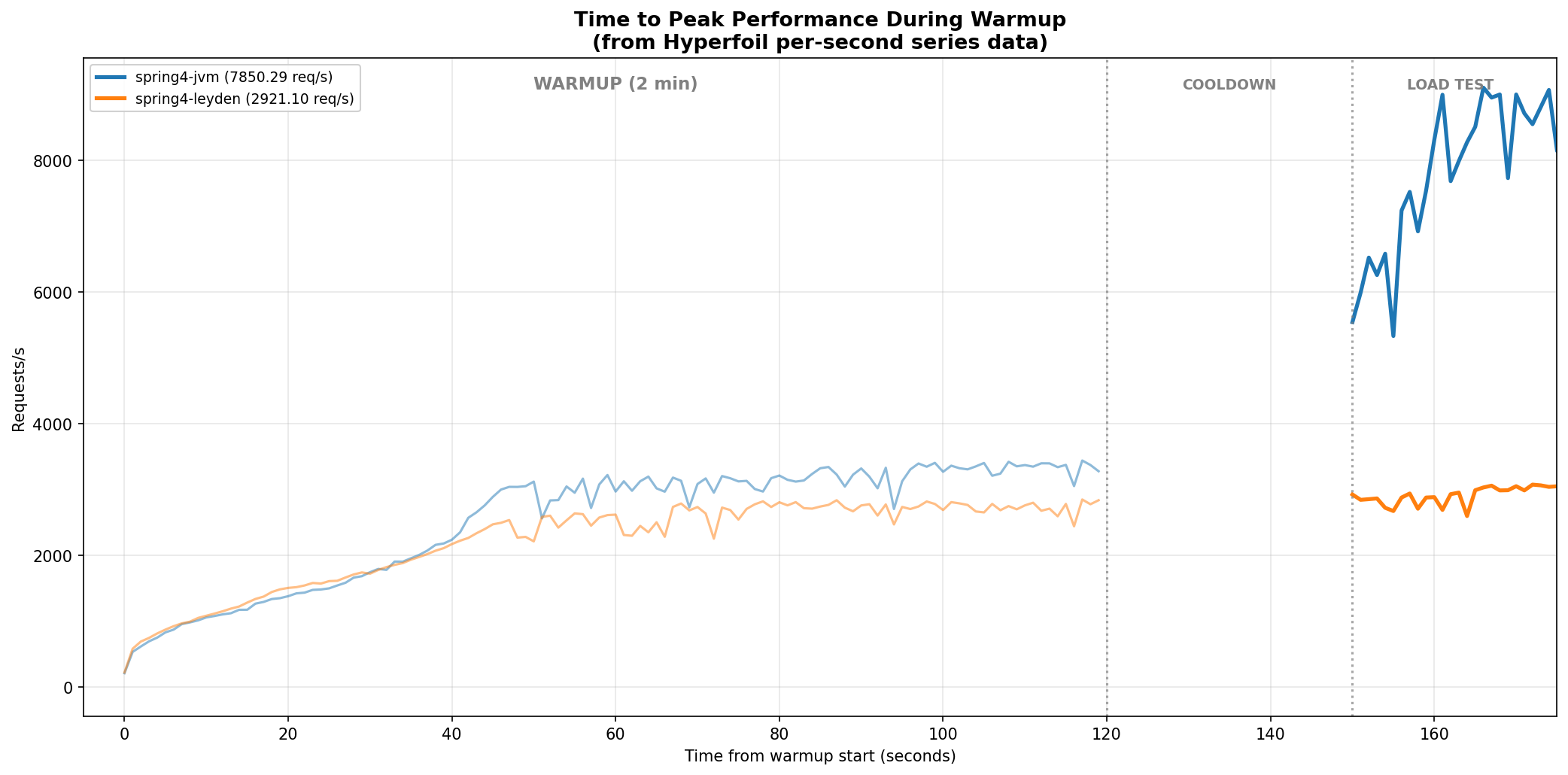
spring4-leyden measures 2,921 TPS after the 2-minute warmup, less than half of spring4-jvm (7,850). The application has not yet reached peak performance when the load test starts. During warmup, the two curves are close for the first 30 seconds, then spring4-jvm pulls ahead while spring4-leyden stalls at ~2,500-3,000.
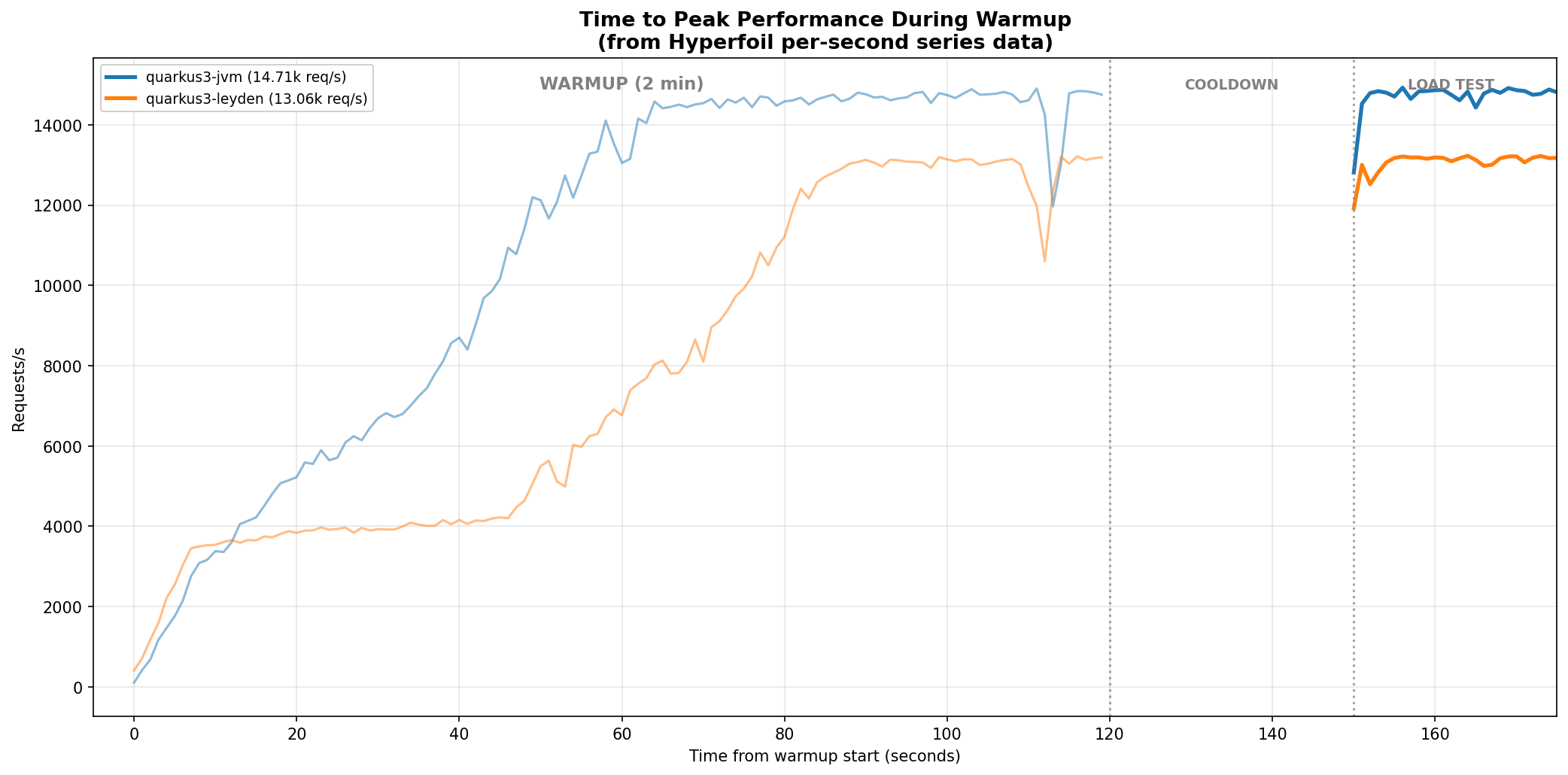
quarkus3-leyden takes ~90 seconds to reach peak, vs ~60 seconds without Leyden. The final throughput is also lower (13,060 vs 14,710). Quarkus’s Leyden integration uses @QuarkusIntegrationTest for training, which exercises actual HTTP endpoints, providing richer profiling data than a startup-only training run. Yet the warmup is still slower.
The C2 compiler thread chart shows the starvation is even worse with Leyden:
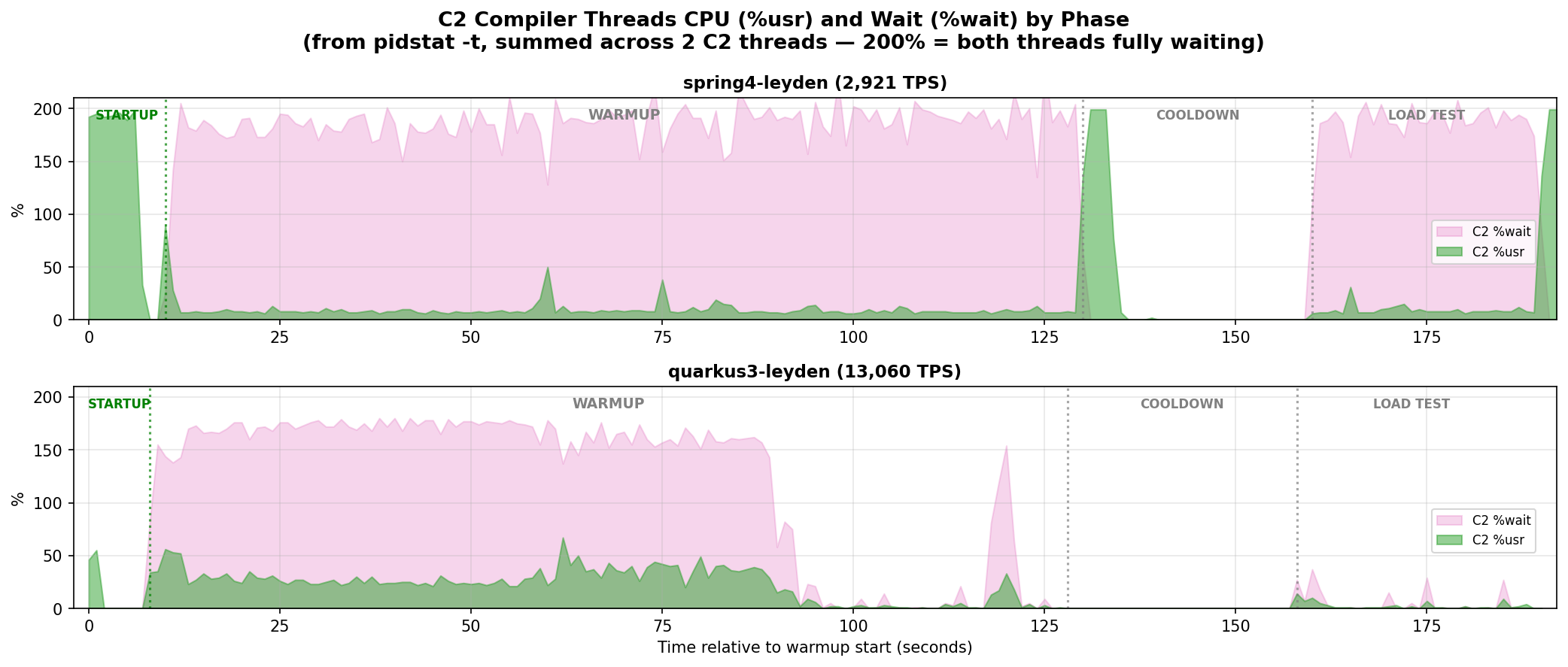
spring4-leyden shows near-200% wait through the entire warmup and into the load test. quarkus3-leyden recovers, but takes ~90 seconds instead of ~60.
As with the non-Leyden case, virtual threads fix the starvation for both frameworks: spring4-virtual-leyden delivers 9,264 TPS (vs 2,921 without virtual threads), a 3x improvement.
Plot twist
While investigating these results, we shared our findings with the OpenJDK community. Ashutosh Mehra from the IBM OpenJDK team looked into the compilation policy and identified JDK-8386852. Normally, the backpressure mechanism described above has a safety net: methods that have been around long enough ("old" methods) get promoted out of tier 2 regardless of queue size. But when AOT training data is present, this safety net is disabled. Methods compiled at tier 2 get stuck there instead of being promoted to tier 3 and tier 4, resulting in fewer C2 compilations and lower peak throughput. Removing this guard in a patched build enables more C2 compilations, improves peak performance, and reduces time to peak for both frameworks. Until this is fixed, Leyden warmup numbers in JDK 25 should not be taken as representative.
|
Troubleshooting hints: To diagnose C2 starvation in your own application, enable JDK Flight Recorder with
Combine with Leyden caveat: enabling JDK Flight Recorder ( |
The OS scheduler matters
All the results above are from our RHEL 9.6 performance lab (kernel 5.14, CFS scheduler). Here is the same benchmark on a local machine running Fedora 43 (kernel 7.0, EEVDF scheduler), same 4 pinned cores and 100 connections:
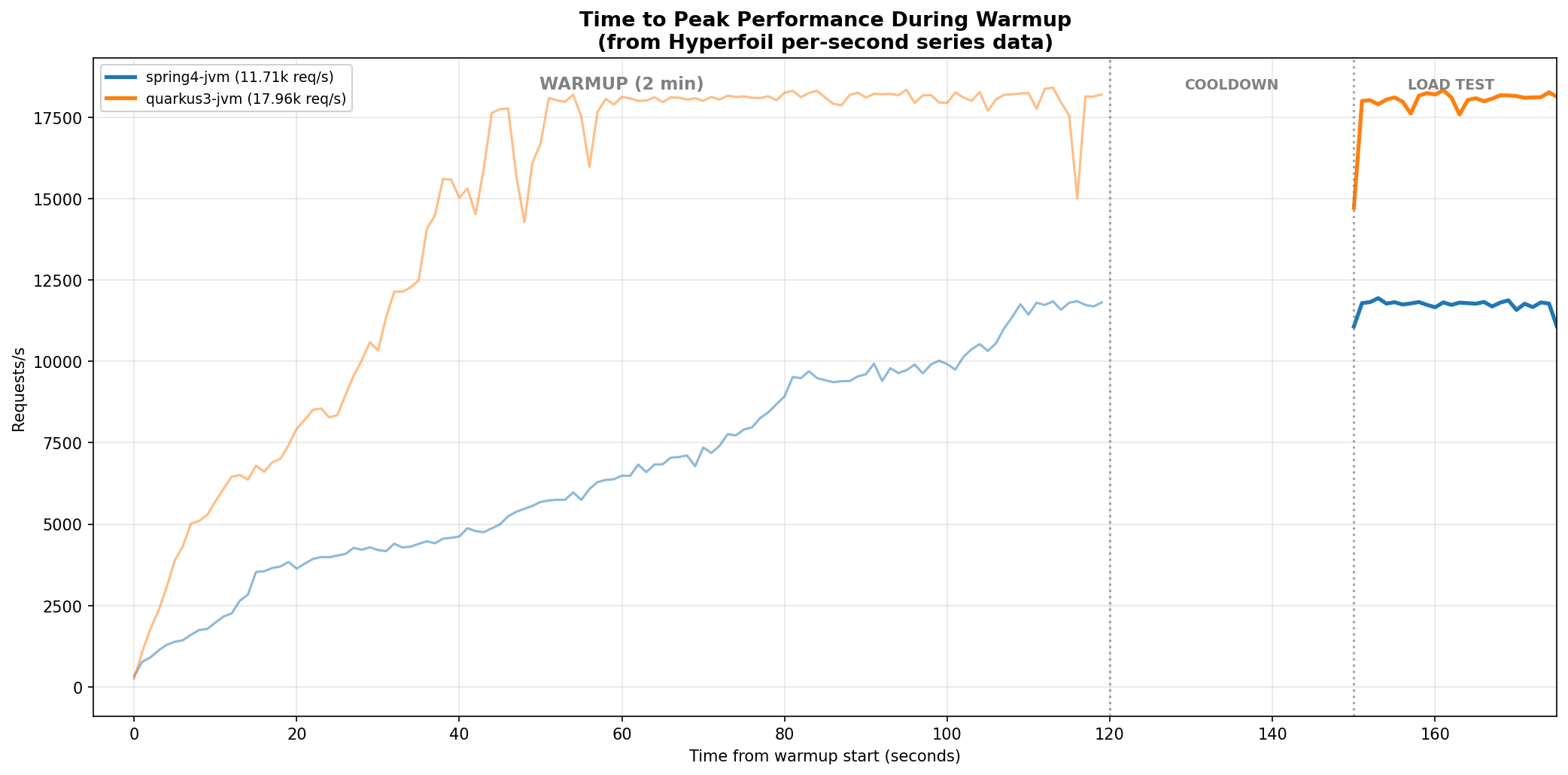
The peak throughput is different because, although clocked at the same speed, this is a different CPU architecture than the lab. The important comparison is the shape of the curve: spring4-jvm now reaches peak during warmup (~110 seconds), while on CFS it was still at ~3,300 req/s after the full 2-minute warmup. Quarkus peaks at ~35 seconds instead of ~60.
For comparison, here is the CFS C2 chart from earlier alongside the EEVDF one:
On EEVDF, C2 threads get significantly more CPU time (green) during warmup. The EEVDF scheduler gives C2 threads more CPU time under contention. It does not eliminate the problem, but it reduces the severity.
Does this happen in production?
Our benchmark uses 4 cores and 100 connections, but production is no different: containerized microservices commonly run with similar CPU budgets and large thread pools. C2 threads get starved, compilations take seconds instead of milliseconds, and pods get killed and restarted before the compiler finishes. The JVM keeps serving requests while broken: liveness probes pass, the application just runs slow code. Without active benchmarking, C2 starvation is invisible.
Leyden’s upcoming AOT Code Compilation (JEP draft 8335368) should help immensely: by caching C2-compiled native code from a training run, the need for runtime C2 activity is heavily reduced. With proper training data that exercises the hot paths, applications could start with optimized code already available, sidestepping the starvation problem entirely.
Takeaways
-
Throughput averages hide warmup problems. Time to peak performance is a separate dimension. An application that delivers good steady-state throughput may take minutes to get there, or never reach it.
-
The C2 compiler needs CPU time. When too many threads compete for the same cores, the C2 threads get preempted. The application runs slower code for longer.
-
Virtual threads help by reducing the number of on-CPU threads, leaving more scheduling time for the compiler. Both frameworks warm up faster with virtual threads.
-
Leaner request processing helps. Quarkus worker threads yield the CPU voluntarily 4x more often than Spring’s, with 20x fewer involuntary preemptions. The compiler gets scheduling gaps to work in.
-
Leyden warmup in JDK 25 is affected by a compilation policy bug. Until this is fixed, and until AOT Code Compilation (JEP draft 8335368) ships, Leyden warmup numbers should not be taken as representative. Virtual threads can recover the lost throughput.
-
The OS scheduler matters. The EEVDF scheduler gives C2 threads more CPU time under contention, reducing the warmup gap. The scheduling algorithm determines how background compiler threads fare.
Tools and data
All data was collected with JDK Flight Recorder, pidstat (-t -u -w), and Hyperfoil. The benchmark, methodology, and data are public: see issue #591 and issue #420. The benchmark code is at commit 38345ca.