SmallRye Stork meets Quarkus

Last week, the Quarkus Insights spotlighted a new project called SmallRye Stork and its integration in Quarkus. In this blog post, we’re going to give you a concise introduction to Stork.
This post has been updated to use the quarkus. prefix when configuring stork properties. This prefix is required since Quarkus 2.8.
|
What’s the problem?
Nowadays, systems we build consist of numerous applications, often called microservices. The system’s overall behavior emerges from the interactions between all these services. So, a microservice is likely going to invoke other ones. But here is the catch. In dynamic environments, such as Kubernetes, or the Cloud, the locations of these services may change over time. So, how does our microservice locate the services it needs to call?
Service discovery solves that problem, as it provides a mechanism to register and find the services. But it leads to another issue. What happens when there are multiple instances of the same service? How does a microservice select the right one? This scenario typically occurs when there are multiple replicas or versions available at the same time. Thus, in addition to service discovery, we need a way to select the right one.
Some environments, e.g., Kubernetes, provide ways to discover service locations and load-balance the traffic. Some do not. In some cases, the capabilities of the environment are not sufficient for the needs of the system.
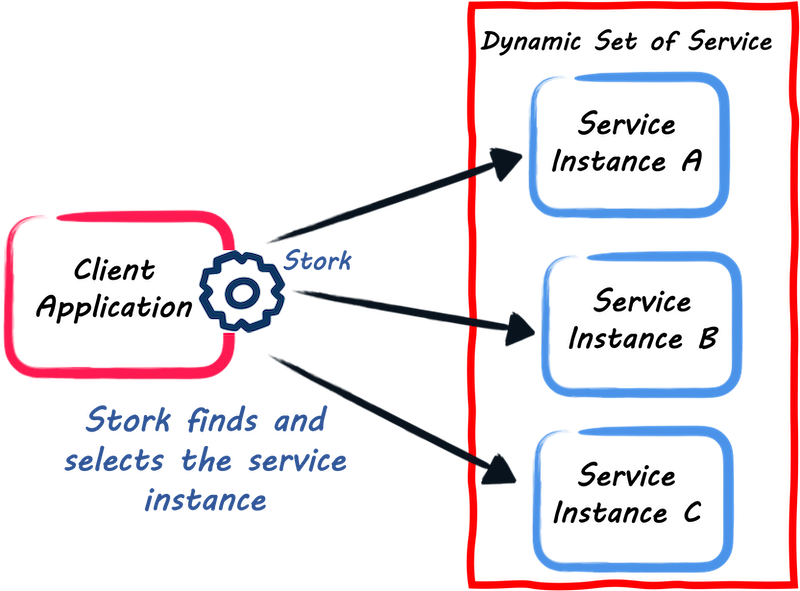
To address these issues, we have created SmallRye Stork. Stork provides both features:
-
service discovery - it lets you locate the service you need to call;
-
service selection - it lets you select the right one when there is more than one instance
What is Stork?
SmallRye Stork is a service discovery and client-side load-balancing framework.
Out of the box, it provides integrations with Hashicorp Consul, Eureka, and Kubernetes and brings in a couple of load-balancer (handling the service selection) implementations, such as round-robin. But the most significant strength of Stork is its extensibility. You can plug your own service discovery mechanism or implement your own, maybe business-related, service selection strategy.
Stork and Quarkus
As of Quarkus 2.5.0.Final, Quarkus gRPC and the Quarkus Reactive REST Client can use Stork to handle the discovery and the selection of the services.
You just need to configure how you want to locate and select your services. The rest will be handled by the clients directly.
For example, to use Stork to determine the actual address for REST Client Reactive, set the scheme of your client’s URI to stork, and the hostname of the URI to the name of the Stork service. If your client’s configKey is my-client, to use it with Hashicorp Consul and the round-robin load balancer, put the following in your `application.properties:
quarkus.rest-client.my-client.uri=stork://hello-service
# configure the discovery and selection of the hello-service
quarkus.stork.hello-service.service-discovery.type=consul
quarkus.stork.hello-service.service-discovery.consul-host=<consul host>
quarkus.stork.hello-service.service-discovery.consul-port=<consul port>
quarkus.stork.hello-service.load-balancer.type=round-robinThe project’s documentation describes step by step how to use Stork with the REST Client, using Consul and round-robin load balancer as examples.
Service selection can be pretty advanced. For instance, the least-response-time strategy monitors the service calls to select the fastest service instance.
| In Quarkus 2.5, the gRPC extension does not propagate statistics of the calls, such as response time or encountered errors. Therefore, a load balancer that relies on this data, such as least-response-time, will not work correctly. We are working on it and hope to have it in Quarkus 2.6. |
A demo and a lot more!
Take a look at the 70th episode of Quarkus Insights for a more detailed explanation and examples.
The demo used this project as the client-side, each of the steps has a corresponding commit in the main branch. The backend services were instances of this project, and the custom service discovery server implementation can be found here.
Conclusion
This post briefly introduces SmallRye Stork and its Quarkus integration. Stork provides a way to locate and select services. It’s simple and customizable. We will cover Stork features in more detail shortly.
If you have ideas for new features, or encounter a bug, please let us know by creating a GitHub issue.