Handling paginated APIs with Mutiny

At the beginning of the Mutiny adventure, my friend Alex came to me with an interesting problem. Alex wanted to retrieve data from a REST service in a reactive manner. So far, no problem, we have everything for this in our toolbox. But, this service, as many services, is using pagination. Ah! That makes things a bit more spicy. Alex wanted to retrieve all the items and consume them as a stream, but you can’t retrieve the items in one batch. You need to invoke the service for every page, extract the items and feed the stream.
So, how to achieve this in a reactive manner and build a proper stream of items without loosing your sanity? Let’s have a look!
The Punk API
First, we need an API. Alex introduced me to the Punk API, a REST API to retrieve beers. That’s fun, and even better, it uses pagination. We got our API!
If you call https://api.punkapi.com/v2/beers?page=1, you get a JSON array like:
[
{
first beer
},
{
second beer
},
// ...
]I won’t show discuss the content of each object, the documentation page does a great job about that.
Let’s focus on the pagination aspect.
First, we passed the page query parameter, indicating which page we want.
Generally, when you retrieve a page, the API provides a way to know if there is a next page (a special field in the JSON document, or HTTP header), but the Punk API does not provide any hint.
So, to retrieve all the beers, we need to invoke the service for page 1, 2, 3… until the returned JSON array is empty.
In an imperative world, to retrieve all the beers, you would do something like this:
List<Beer> beers = ...;
int page = 1;
List<Beer> batch = ...
do {
batch= getBeersFromPage(page);
beers.addAll(batch);
page = page + 1;
} while (! batch.isEmpty());How can we achieve the same in a reactive manner and build a stream of beer?
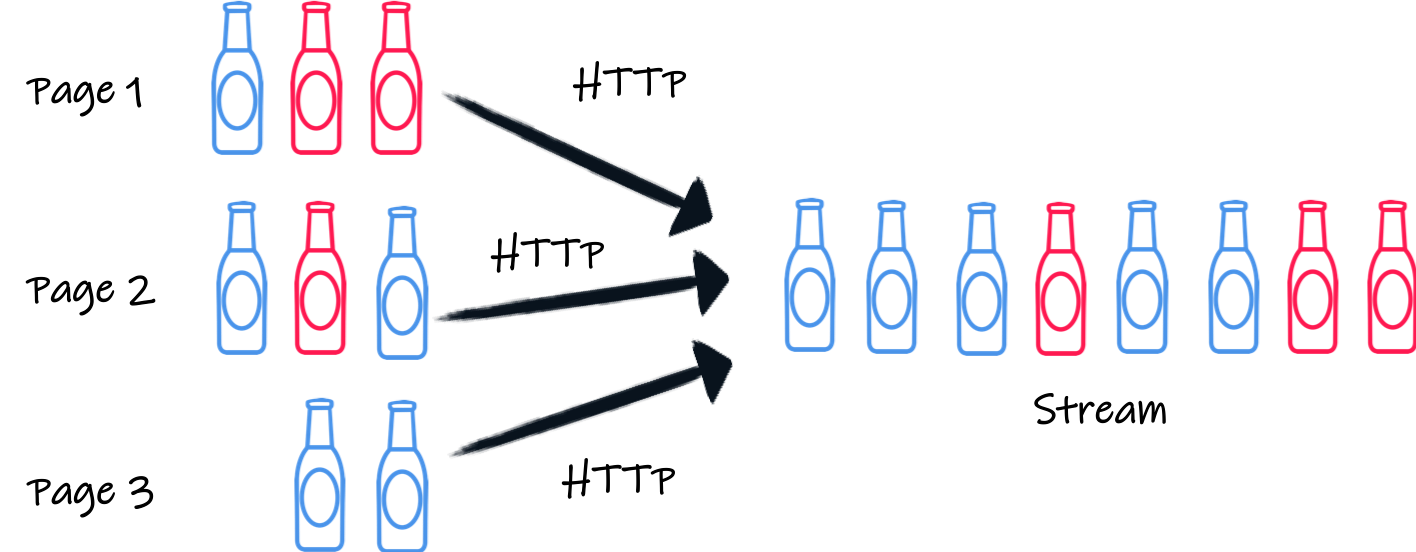
Let’s proceed step by step.
Retrieving a single page
First, we need to see how we can retrieve a single page. I’m going to use the Vert.x Web Client, but you can use any reactive HTTP clients providing a Mutiny API.
// Create the client
WebClient client = WebClient.create(vertx, new WebClientOptions()
.setDefaultHost("api.punkapi.com")
.setDefaultPort(443)
.setSsl(true)
);
// Retrieve the first page
Uni<List<Beer>> uni = client.get("/v2/beers?page=1")
.send()
.onItem().transform(Pagination::toListOfBeer);This snippet creates the web client. Then, we use that client and retrieve the first page.
When we receive the result (onItem), we transform the JSON array into a list of beers.
Let’s extract this code in a method and take the page number as parameter:
private static Uni<List<Beer>> getPage(WebClient client, int page) {
return client.get("/v2/beers?page=" + page)
.send()
.onItem().transform(Pagination::toListOfBeer);
}So far, so good.
Retrieving multiple page
So, now, we know how to retrieve a single page and extract the items from it. We just need to repeat this operation for every page, and provide a stream.
Mutiny provides a method to create a Multi by repeating multiple times a Uni.
Under the hood, it calls a method returning a Uni and subscribe on it.
But we need to make progress, and pass the current page.
Mutiny offers the possibility to store a state in order to let the method creating the Uni increments the page number:
Multi.createBy().repeating().uni(AtomicInteger::new, page ->
getPage(client, page.incrementAndGet())
)This code above creates a stream with the item emitted by the Unis returned by the getPage method.
We increment the page number (stored in an AtomicInteger) every time.
So, it retrieves the page 1, 2, 3 … and every time emits the received List<Beer> downstream.
However, at some point, we must stop. As we said earlier, we can stop when the returned list is empty:
Multi<List<Beer>> multi = Multi.createBy().repeating().uni(AtomicInteger::new, page ->
getPage(client, page.incrementAndGet())
)
.until(List::isEmpty);The until clause indicates when the iteration must be stopped.
It receives the retrieved list (produced by getPage), and when this list is empty, stops the repetition.
If the list still contains beers, it retrieves the next page.
Unpacking the beers
We now have a stream of list, and each list contain a set of beers. We are almost there, but Alex wants a stream of beer. So we need to unpack the beers.
The first approach to achieve this uses transformToMultiAndConcatenate, i.e. for each list create a new multi with the contained beers and concatenate these multis:
Multi<Beer> multi = Multi.createBy().repeating().uni(AtomicInteger::new, page ->
getPage(client, page.incrementAndGet())
)
.until(List::isEmpty)
.onItem().transformToMultiAndConcatenate(l -> Multi.createFrom().iterable(l));
Wondering about concatenate? Check out this other blog post
|
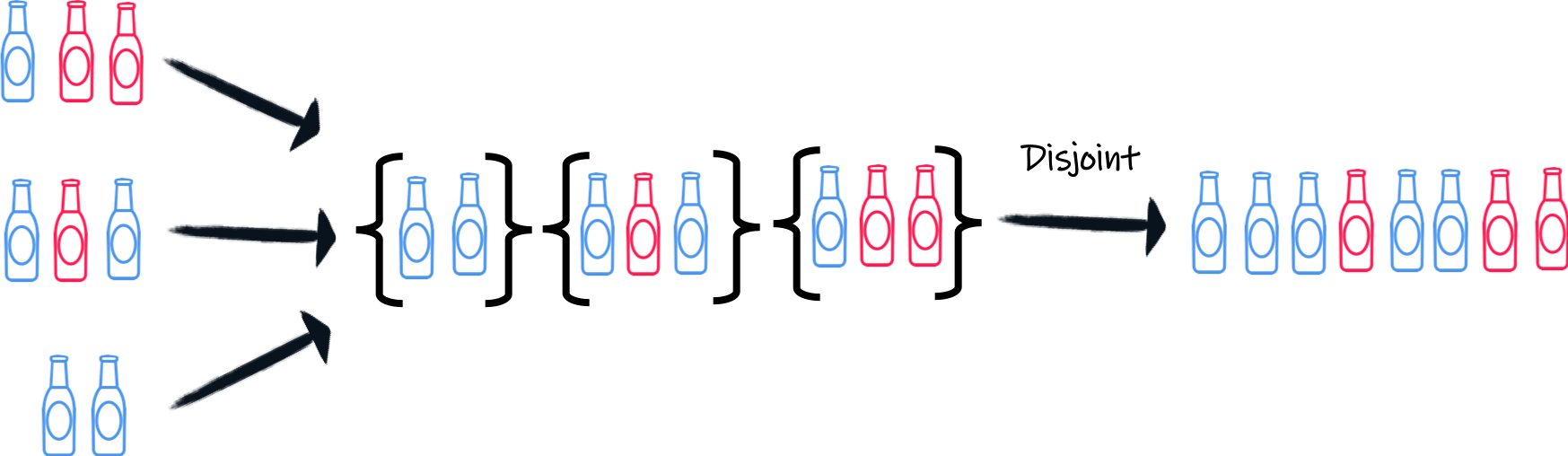
Because this is a common operation, Mutiny provides the disjoint method doing exactly the same:
Multi<Beer> multi = Multi.createBy().repeating().uni(AtomicInteger::new, page ->
getPage(client, page.incrementAndGet())
)
.until(List::isEmpty)
.onItem().disjoint();And we are done!
The benefits of reactive
We have our stream, it’s time to use it! Let’s, for example, retrieve the first 10 beers with "IPA" (let’s be trendy) in their description:
multi
.transform().byFilteringItemsWith(beer -> beer.description.contains("IPA"))
.transform().byTakingFirstItems(10);The advantage of our stream is that we won’t retrieve every page. As soon as we have enough beers, we stop the repetition. How? Because it informs the upstream that it does not need more items (cancellation) and that stops the repetition. So, retrieving items from paginated APIs this way can reduce the number of requests and, as a consequence the load on the remote service.
Feel thirsty?
Wanna try this code, checkout this gist. You can run it immediately with jbang:
jbang https://gist.github.com/cescoffier/18a326a5c057392bec54d95ec5a06ca6