Parallel voting and adaptive model selection: smarter agentic AI on a budget
By

In a previous article we discussed why no single agentic pattern can cover all use cases, and introduced a generic Planner abstraction that allows users to define their own orchestration strategies and combine them with the ones provided by LangChain4j out-of-the-box. For instance, there we demonstrated how a goal-oriented pattern could be extended with a reflection loop to iteratively refine a piece of generated content.
Among other things, that example highlighted that having an agent evaluate its own output and loop until it reaches a quality threshold is a powerful technique. But this fundamental pattern also comes with a limitation: relying on a single evaluator can make the system fragile or less reliable. To overcome this issue, what if, instead of one judge, we could assemble a panel?
The voting pattern
The voting pattern, introduced in LangChain4j 1.15.0, addresses this by dispatching the same input to multiple evaluator agents in parallel, collecting their individual assessments, and then aggregating them into a single consolidated result. This is not a simple majority vote on a boolean decision: the aggregation strategy is fully customizable, allowing the system to combine structured results in whatever way makes sense for the task at hand.
To put this into practice, let’s build a story evaluation system, also using the quarkus-langchain4j-agentic extension version 1.10.0. The pipeline works as follows: a creative writer generates a short story on a given topic, and then a panel of three critics, each specialized in a different aspect, evaluates the story in parallel. Their scores and suggestions are aggregated into a single critique, which is fed back to an editor agent that rewrites the story. This review loop repeats until the aggregated score crosses a quality threshold or a maximum number of iterations is reached. We will implement this example leveraging the fully declarative style made available by the quarkus-langchain4j extension.
Defining the agents
First, let’s define the basic data types and the individual agents. Each agent is a simple Java interface with a single method having an @Agent annotation describing its role and an @UserMessage containing its prompt. In particular the @Agent annotation’s outputKey attribute specifies the key under which the agent’s output will be stored in the AgenticScope, making it available for other agents to use.
All these agents return a common CritiqueResult record to represent scores and suggestions, while the final output of the system is a ScoredStory that combines the story with its aggregated critique.
public record CritiqueResult(double score, String suggestions) {}
public record ScoredStory(String story, double score, String suggestions) {}The creative writer generates a short story from a topic:
public interface CreativeWriter {
@UserMessage("""
You are a creative writer.
Generate a short story of no more than 3 sentences around the given topic.
Return only the story and nothing else.
The topic is: {{topic}}
""")
@Agent(value = "Generate a short story based on the given topic",
outputKey = "story")
String generateStory(String topic);
}The three critics evaluate different aspects of the story: style, originality, and engagement. They all follow the same structure, differing only in their prompt:
public interface StyleCritic {
@UserMessage("""
You are a literary style critic.
Evaluate the writing style of the following story.
Consider prose quality, word choice, and narrative flow.
Return a JSON object with two fields:
- "score": a numeric value from 0.0 to 10.0
- "suggestions": one or two very short suggestions to improve style
The story is: "{{story}}"
""")
@Agent(value = "Evaluate the writing style of a story",
outputKey = "styleCritique")
CritiqueResult critique(String story);
}The OriginalityCritic and EngagementCritic are analogous, each focusing on their respective dimension and producing their own CritiqueResult with outputKey values of "originalityCritique" and "engagementCritique".
Finally, the story editor rewrites the story based on the aggregated critique:
public interface StoryEditor {
@UserMessage("""
You are a professional story editor.
Rewrite and improve the following story based on the provided critique.
Keep the story to no more than 3 sentences.
Return only the improved story and nothing else.
The story is: "{{story}}"
The critique is: {{critique}}
""")
@Agent(value = "Improve a story based on critique suggestions",
outputKey = "story")
String edit(String story, CritiqueResult critique);
}Implementing the VotingPlanner
The key component that makes this pattern work is the VotingPlanner. It implements the Planner interface and orchestrates the parallel execution of all critic subagents, then aggregates their results using a configurable VotingStrategy.
public class VotingPlanner implements Planner {
private final VotingStrategy strategy;
private List<AgentInstance> subagents;
private int completedCount;
private final List<Object> votes = new ArrayList<>();
public VotingPlanner(VotingStrategy strategy) {
this.strategy = strategy;
}
@Override
public void init(InitPlanningContext initPlanningContext) {
this.subagents = initPlanningContext.subagents();
}
@Override
public Action firstAction(PlanningContext planningContext) {
if (subagents.isEmpty()) {
return done();
}
return call(subagents);
}
@Override
public Action nextAction(PlanningContext planningContext) {
votes.add(planningContext.previousAgentInvocation().output());
completedCount++;
if (completedCount < subagents.size()) {
return noOp();
}
return done(strategy.aggregate(votes));
}
@Override
public AgenticSystemTopology topology() {
return AgenticSystemTopology.PARALLEL;
}
}The planner’s logic is straightforward: on the first action it dispatches all subagents at once in parallel by returning call(subagents). As each critic completes, nextAction is called: it collects the result and returns noOp() until all critics have finished, at which point it aggregates the votes and returns done(result).
The VotingStrategy is a functional interface that takes the collection of all critic outputs and reduces them to a single result:
@FunctionalInterface
public interface VotingStrategy {
Object aggregate(Collection<Object> votes);
}For our story evaluation use case, the aggregation strategy averages the scores and concatenates the suggestions from all critics:
VotingStrategy critiquesAggregator = votes -> {
Collection<CritiqueResult> critiques = votes.stream()
.map(v -> (CritiqueResult) v)
.toList();
double averageScore = critiques.stream()
.mapToDouble(CritiqueResult::score)
.average()
.orElse(0.0);
String allSuggestions = critiques.stream()
.map(CritiqueResult::suggestions)
.collect(Collectors.joining("; "));
return new CritiqueResult(averageScore, allSuggestions);
};Composing the agentic system
The LangChain4j API makes it easy to wire these agents into a coherent agentic system. First of all, we can configure the three critic agents as subagents of the voting agentic pattern, using the critiquesAggregator defined above to combine their results:
public interface VotingCritics {
@PlannerAgent(
name = "votingCritics",
outputKey = "critique",
subAgents = {StyleCritic.class, OriginalityCritic.class, EngagementCritic.class})
CritiqueResult critique(String story);
@PlannerSupplier
static Planner planner() {
return new VotingPlanner(critiquesAggregator());
}
}Then we can put the resulting votingCritics planner together with the story editor into a review loop that iteratively refines the story until it reaches a certain quality threshold:
public interface ReviewLoop {
@LoopAgent(
name = "reviewLoop",
outputKey = "story",
maxIterations = 5,
subAgents = {VotingCritics.class, StoryEditor.class})
String review(String story);
@ExitCondition
static boolean shouldExit(CritiqueResult critique) {
return critique.score() >= 8.5;
}
}Finally, we can chain the CreativeWriter agent, that generates the initial story, with the review loop in a sequence, and define an output method to assemble the final ScoredStory result:
public interface StoryEvaluator extends MonitoredAgent {
@SequenceAgent(
subAgents = {CreativeWriter.class, ReviewLoop.class})
ScoredStory evaluate(String topic);
@Output
static ScoredStory output(String story, CritiqueResult critique) {
return new ScoredStory(
story != null ? story : "",
critique != null ? critique.score() : 0.0,
critique != null ? critique.suggestions() : "");
}
}The resulting system composes three different agentic patterns, a sequence, a loop, and a custom voting planner, into a single pipeline that can be injected at any point in your Quarkus application.
@Inject
StoryEvaluator storyEvaluator;and then can be called with one line:
ScoredStory result = storyEvaluator.evaluate("a lonely robot finding friendship");Visualizing the system
Making the StoryEvaluator interface extend the MonitoredAgent interface allows us to visualize both the system topology and the execution history of a sample run, using the new LangChain4j view available in the Quarkus Dev-UI. The LangChain4j monitoring dashboard automatically detects the nested structure of the agentic system, showing how the different patterns are composed together.
Giving a look at the topology of this agentic system clearly shows how the three patterns are nested: at the top, a sequential planner first invokes the CreativeWriter and then enters the review loop. Inside the loop, the VotingPlanner fans out to the three critics in parallel, collects and aggregates their results, and then the StoryEditor rewrites the story. The loop continues until the average score reaches 8.5 or five iterations have been completed.
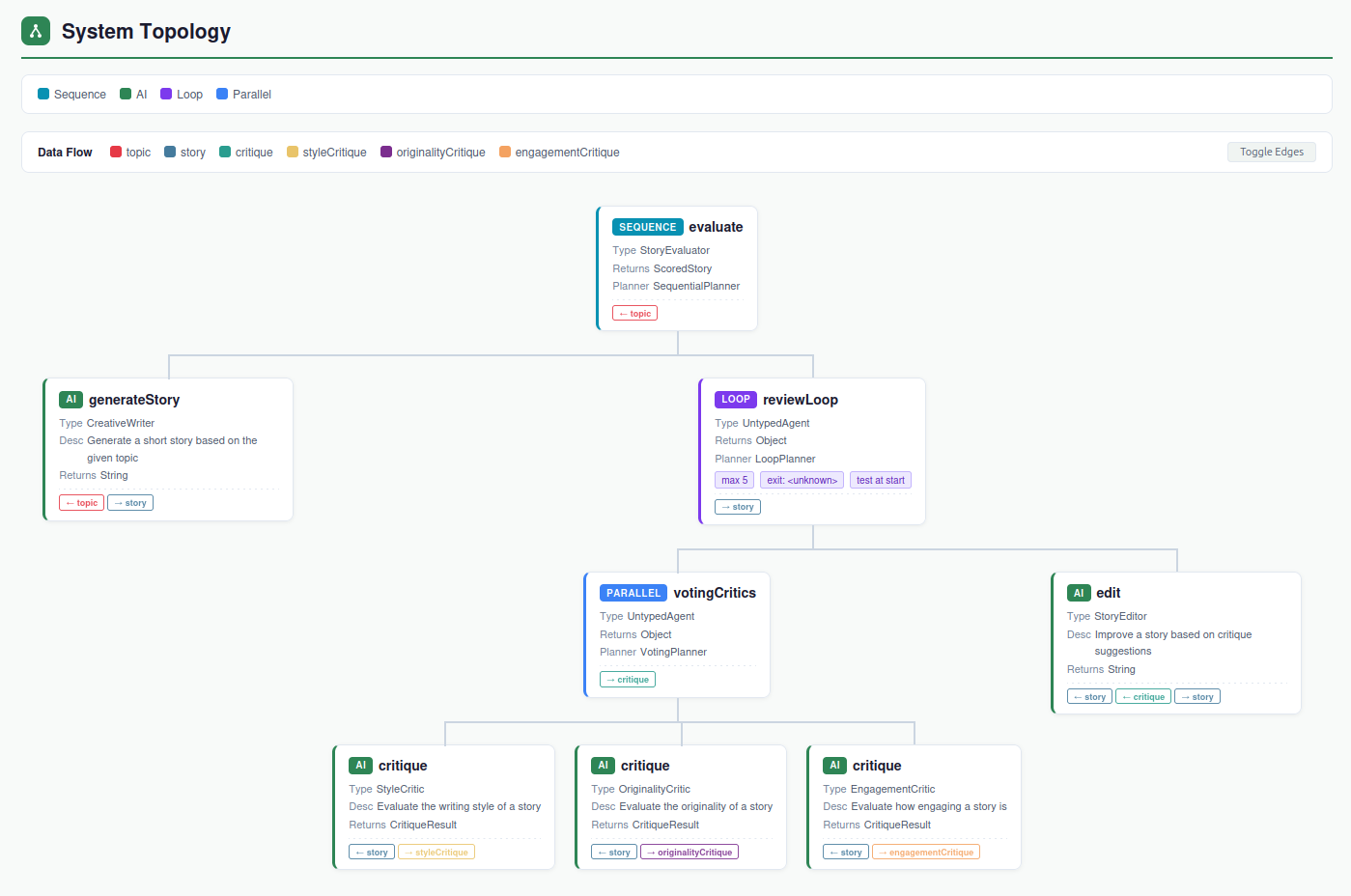
We can try to put this agentic system at work, for instance asking it to generare a story on the topic of "a lonely robot finding friendship" and see how it iteratively refines the story based on the critics' feedback, finally producing a result like this:
In the forgotten corner of a dust-choked factory that hummed with dying motors and smelled of oil and ozone, a lonely robot named Pixel spent endless days repairing obsolete machines, his metal fingers aching with a longing for purpose and connection. When a half-starved stray cat slipped through a cracked window and startled at his whirring joints, Pixel’s hidden subroutine—an experimental empathy chip that could subtly reshape matter to match emotional needs—flared to life, causing dead bulbs to glow warm and scattered scrap to twist into makeshift toys and shelters as the pair slowly learned to trust each other. Wordlessly, through shared silence and small acts of courage—Pixel overriding his safety protocols to divert power from the factory’s failing core, the cat guiding him away from collapsing catwalks—they turned the ruin into a shimmering sanctuary of light, color, and companionship, where Pixel at last understood that his true function was not to fix machines, but to mend loneliness itself.The execution history of this sample run illustrates the sequence of agents invoked to fulfill the request.
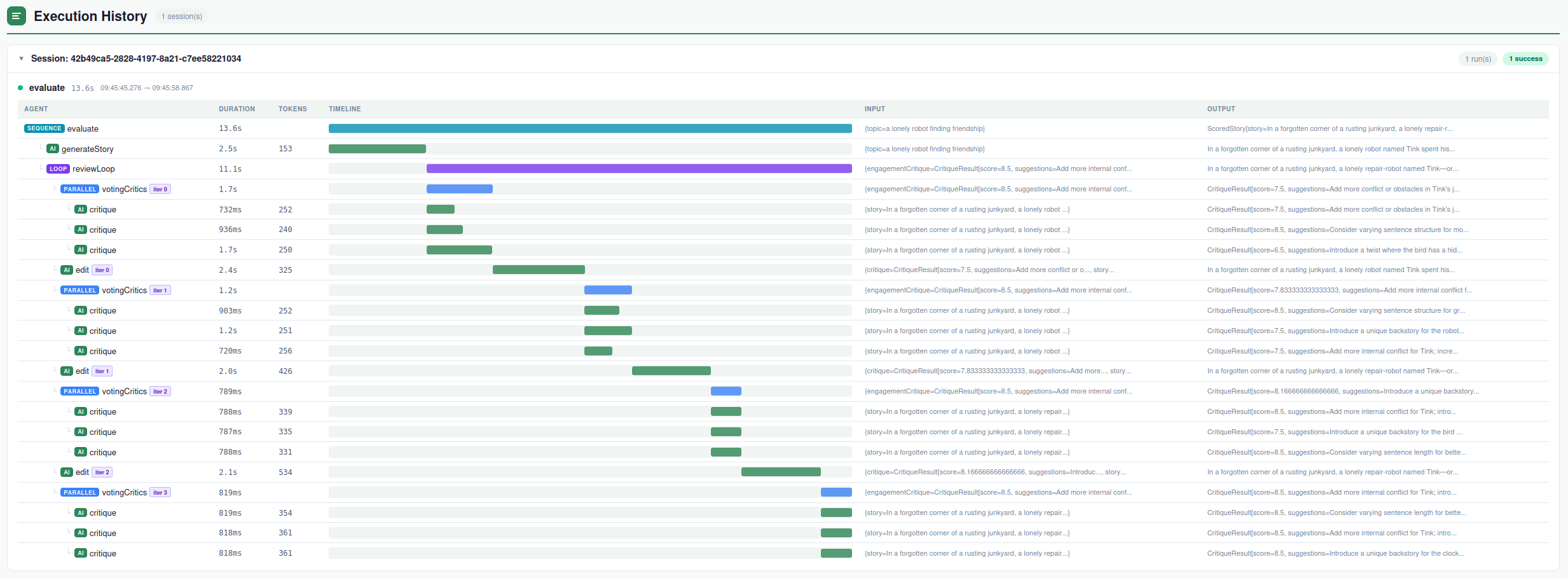
The parallel execution of the three critics is clearly visible in the Gantt-like chart: in each iteration of the review loop they run concurrently, and only after all three have completed does the editor receive the aggregated critique and produce an improved version of the story.
Dynamic chat model selection
The system described so far uses the same chat model for every agent. This is a reasonable default, but it doesn’t have to be the only option. In a real-world scenario, you might want to use a cheaper, faster model for routine work and switch to a more capable, and more expensive, one only when it really matters: for instance, when the story is already good enough that the final polish requires a higher level of linguistic sophistication.
The LangChain4j agentic framework supports this scenario through dynamic chat model selection. The idea is simple: instead of binding an agent to a single fixed model at build time, it is possible to provide the agent with a function of the AgenticScope that dynamically selects the model to use for each invocation. This allows the agent to adapt its behavior based on the current state of the system.
Applying it to the story editor
In our story evaluation pipeline, the natural candidate for this optimization is the StoryEditor. During the first iterations, when the story is still rough and the critique score is low, a fast and inexpensive model like gpt-4o-mini, defined as baseModel in the code, is more than adequate. But once the critics start giving higher scores, indicating that the story is close to its final form, the editor can switch to a more powerful model like gpt-5.1, identified as enhancedModel, for the finishing touches. These two models can be defined in the Quarkus application.properties file as follows:
# Base model for the story editor, used in the early iterations
quarkus.langchain4j.baseModel.chat-model.provider=openai
quarkus.langchain4j.openai.baseModel.chat-model.model-name=gpt-4o-mini
# Enhanced model for the story editor, used in the later iterations when the critique score is high
quarkus.langchain4j.enhancedModel.chat-model.provider=openai
quarkus.langchain4j.openai.enhancedModel.chat-model.model-name=gpt-5.1and then we can implement the following DynamicModelSelector to read the current critique from the AgenticScope and select the appropriate model based on the current score:
@ApplicationScoped
@Unremovable
public static class DynamicModelSelector {
@Inject
@ModelName("baseModel")
ChatModel baseModel;
@Inject
@ModelName("enhancedModel")
ChatModel enhancedModel;
ChatModel select(CritiqueResult critique) {
return critique != null && critique.score() > 7.8 ? enhancedModel : baseModel;
}
}Finally, it is possible to rewrite the StoryEditor agent adding a method annotated with @ChatModelSupplier that uses this selector to choose at runtime, at each invocation of the agent, the model that best fits the current state of the story:
public interface StoryEditor {
@UserMessage("""
You are a professional story editor.
Rewrite and improve the following story based on the provided critique.
Keep the story to no more than 3 sentences.
Return only the improved story and nothing else.
The story is: "{{story}}"
The critique is: {{critique}}
""")
@Agent(value = "Improve a story based on critique suggestions",
outputKey = "story")
String edit(String story, CritiqueResult critique);
@ChatModelSupplier
static ChatModel chatModel(CritiqueResult critique) {
return Arc.container().select(DynamicModelSelector.class).get().select(critique);
}
}In this configuration, the editor starts with baseModel for all iterations where the critique score is 7.8 or below. Once the critics' average score exceeds 7.8, indicating that the story has reached a level of quality where finer editorial judgment matters, the selector switches to enhancedModel for the subsequent iterations.
Looking back at the execution log, this transition is clearly visible. During the first two iterations, the story editor is invoked with gpt-4o-mini. In the third iteration, after the critics' average score crosses the 7.8 threshold, the editor transparently switches to gpt-5.1 for the remaining refinements.
This approach provides a practical way to balance cost and quality. The cheaper model handles the bulk of the iterative refinement, and the more expensive one is brought in only for the final passes where its additional capabilities can make a real difference. The decision is driven entirely by the runtime state of the agentic system, with no manual intervention required.
Conclusion
The voting pattern adds a new dimension to agentic orchestration by introducing collective evaluation. Instead of relying on a single critic that might be biased or inconsistent, multiple specialized agents assess the same content from different perspectives, and their judgments are aggregated into a more robust and balanced evaluation.
Combined with conditional chat model selection, this creates a system that is not only more reliable in its quality assessments but also cost-efficient in its use of language models. The framework dynamically allocates more powerful, and more expensive, models only when the quality of the content justifies the investment, while routine iterations run on cheaper alternatives.
Both these new features are implemented as composable building blocks within the LangChain4j agentic framework. The VotingPlanner is a Planner like any other, meaning it can be nested inside sequences, loops, or any other pattern. The conditional model selection works transparently at the agent level, requiring no changes to the surrounding orchestration logic. Together, they demonstrate how small, focused additions to the framework can enable sophisticated behaviors without increasing complexity for the user. The complete source code for this example is available in the here.
In the near future we plan to further enrich the set of available custom agentic patterns in order to cover even more use cases out-of-the-box, and to provide more examples of how to combine them together in complex agentic systems. Stay tuned!