Introducing Quarkus Data: One Gateway for Data Access
By

Quarkus Data: One Gateway for Data Access
You might have read Stephane’s blog post about Panache Next, the new version of Panache that we’re currently developing, and his follow-up on the renaming to Quarkus Data. This blog post is about what comes next.
Having discussed current database access patterns in conferences, meetings and user feedback sessions, we know that the current implementation of Panache, which we’ll call Panache 1 in this blog post, is popular as a data access mechanism. But despite Panache 1’s popularity, we discovered that there is some confusion on exactly what Quarkus extension to use.
Should a Quarkus application that needs database access use the Hibernate extension, the Hibernate Reactive extension, Panache, or something else? Given that Hibernate is currently the most popular extension in Quarkus (as most applications will need persistence on the database), you might imagine that this confusion is creating some friction.
Try it yourself: create a Quarkus app with the CLI, then search for a database extension:
quarkus create app myapp
cd myapp
quarkus extension add jpa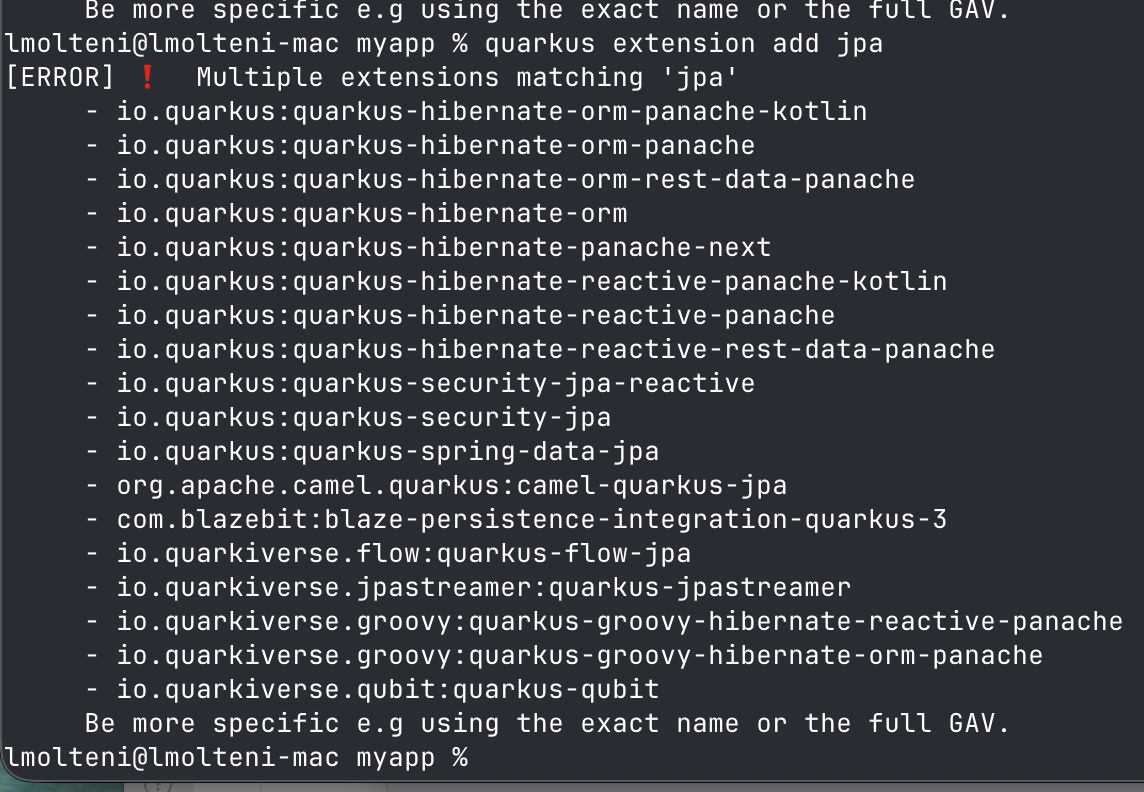
That’s a lot of results. Some of them are not obviously related, but the ones on top are misleading. And if you try searching for "database" instead, it’s even worse:
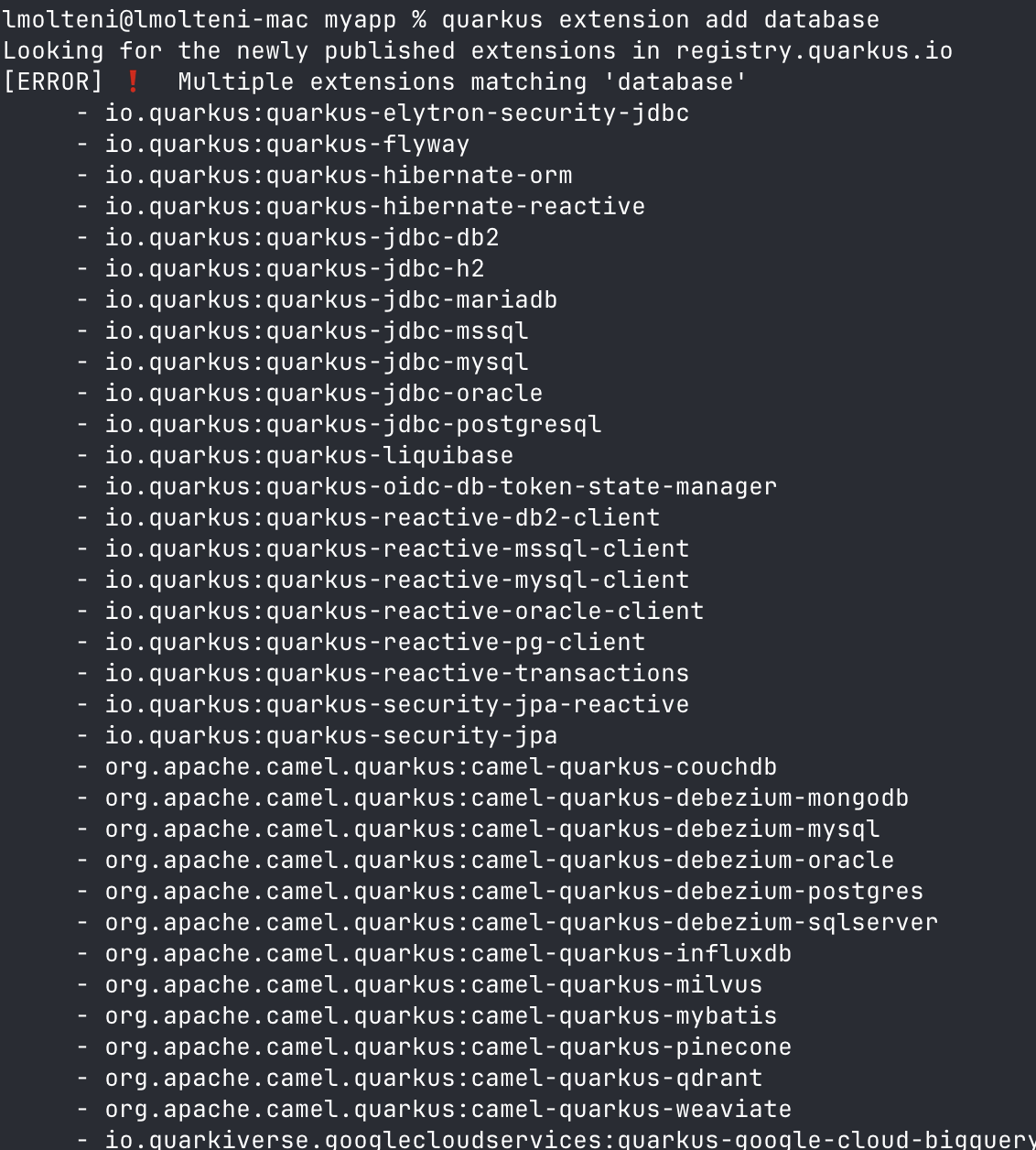
Which one do you pick?
From Panache to Jakarta Data
This situation is admittedly confusing, but it didn’t happen by accident. Every one of those extensions exists because it solves a real problem. To understand how we got here, we need to go back to the early days of Quarkus.
Developers wanted a simple way to avoid writing repetitive data access code: define an entity, get basic CRUD operations, and declare queries in a single place without writing similar query methods by hand. Also, developers love the idea of the "repository class", a class that will hold such queries and some helpers to avoid writing code. At the time, there was no standard repository pattern for Hibernate, so the Quarkus team created Panache to fill that gap. Panache provided a repository pattern, a single place to define queries for each entity, and also offered richer entities to simplify data access by putting persistence methods directly on their entities.
Since then, the Jakarta EE ecosystem has caught up. Jakarta Data [jd] standardizes the repository pattern across SQL and NoSQL databases, with an annotation processor that generates implementations at compile time, including full type checking of queries and parameter bindings against your entity model. It is a top-level specification in Jakarta EE 11 that supports both Jakarta Persistence and Jakarta NoSQL [nosql]. With Jakarta Data now providing some of the features Panache pioneered, it was natural for the Quarkus team to build on it.
Introducing Quarkus Data
We then created "Quarkus Data": an umbrella project for data access in Quarkus. It groups all data access extensions we showed earlier under a single name, making it easier to find documentation and understand how the pieces fit together. This is the biggest change to data access in Quarkus since the introduction of Panache, and we believe it’s a step forward for both new and existing users. It’s the first part towards a better user experience for newcomers, but it’s not yet done: having a new extension means having more complexity, not less. Part of the future work will be to make Quarkus Data the obvious entry point across the CLI tools, the documentation, code.quarkus.io, and other places.
|
Why "Quarkus Data" and not "Panache 2.0"?
The Panache name was popular with our users, but it had a discoverability problem. "Hibernate with Panache" was meant to signal a better Hibernate experience, but if you didn’t already know what Panache was, the name didn’t tell you. A user searching for "hibernate" or "data" would see Panache in the results, but nothing about the name suggested it was the simpler way to do repositories, or any of its other features. We chose "Data" because the project is built on Jakarta Data, it’s self-explanatory, and it might help users migrating from other frameworks as they’re already used to the "Data" naming, i.e. Spring, Micronaut, Helidon… It’s also an opportunity to create an umbrella that covers both SQL and NoSQL under the same name. |
Under the Quarkus Data umbrella, there can be specific modules for different backends. The first one is Quarkus Data Hibernate, for relational databases. In the future, additional modules like Quarkus Data MongoDB could follow the same model for NoSQL databases.
Quarkus Data Hibernate
Quarkus Data Hibernate is now the new entry point for relational database access in Quarkus. If you need to talk to a database, this is the one extension you add:
quarkus extension add quarkus-data-hibernateOr in your pom.xml:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-data-hibernate</artifactId>
</dependency>This single extension gives you everything you need to start with data access in your application. It’s structured in a way that makes "simple things easy, and complex things possible". This means that it offers an experience that is enjoyable for newcomers to Hibernate, without limiting advanced users from using advanced features.
Here’s a round-up of the features it offers:
-
Richer entities: your entity gets lifecycle operations by extending a simple class. The simplest way to get started.
-
Repositories: define a standalone repository interface annotated with
@Repository, along with queries consisting simply in strings using the HQL/JPQL languages from Jakarta Persistence. The Hibernate annotation processor generates the implementation at compile time, with full type checking of queries and parameters against your entity model. -
Stateless and Managed session: Explicit lifecycles for simple cases, all the power of Hibernate managed objects when you need it.
-
Reactive: The same entity model and project work in both blocking and non-blocking modes, useful when you need to integrate with reactive code.
-
Raw SQL: write native SQL queries using
@SQLon a repository method when writing SQL is easier. No entity mapping required.
|
While Quarkus Data Hibernate is the main entry point, some features require an additional dependency to keep the default footprint small.
For example, reactive support requires adding |
We’ll publish a hands-on tutorial shortly that walks through each style with working examples, so stay tuned.
What about Panache 1?
Panache 1 is not going away. It will remain available as an extension for existing applications, and we have no plans to remove it.
That said, Quarkus Data Hibernate is where all new development and investment is happening. If you’re starting a new project, we’d encourage you to give it a try. We really believe it’s a better experience. The extension is still experimental, so you might find some bugs. If you do, please reach out to us either on GitHub or Zulip, we always appreciate your honest feedback.
We are working on migration tooling to help existing Panache 1 users transition when they are ready, and we will share more details as that work progresses.
Try it today
You can try Quarkus Data Hibernate today from Quarkus 3.37.0. It will also ship as part of Quarkus 4.0.
Give it a try and let us know what you think. Feedback is welcome on Zulip or via GitHub issues.
References
-
[nosql] NoSQL and Persistence explained — how Jakarta Data supports both Jakarta Persistence and Jakarta NoSQL
-
Jakarta Data creation review — Eclipse Foundation approval (2022)
-
Gavin King on repositories and annotation processing — what made compile-time validation the turning point