Experimental GraphQL

This blog post is a follow up on the initial introductory post, Supersonic Subatomic GraphQL, and here we will explore more features, some that is experimental, that we hope to eventually move to the MicroProfile GraphQL Specification (based on your feedback !)
We will look at the following:
-
Operational Context - Optimize your downstream processes.
-
Cache - Caching your endpoints.
-
Asynchronous - Concurrent execution of multiple requests or sources.
-
Batch - Solving N+1.
-
Generics support.
-
Events and custom execution.
-
Transformation and mapping.
-
Build tools - Maven and Gradle support.
All source code is available here: github.com/phillip-kruger/graphql-experimental
Operational Context
The Context Object is an experimental Object that can be injected anywhere in your code, downstream from your @GraphQLApi.
It’s in the api module in SmallRye GraphQL, with the intention to eventually move this up to the MicroProfile GraphQL Api.
Example:
We have a Person GraphQL Endpoint, that uses some service to get the person from where ever it is stored.
The endpoint:
@GraphQLApi
public class PersonEndpoint {
@Inject
PersonService personService;
@Query
public List<Person> getPeople(){
return personService.getAllPeople();
}
@Query
public Person getPerson(int id){
return personService.getPerson(id);
}
}A Person is a basic POJO, that can have multiple relationships, that in turn has a Person. So making a call to the database to get a person, can end up retuning more people, depending on the number of relationships. In our example, we have Person 1 that has a Spouse, Person 2.
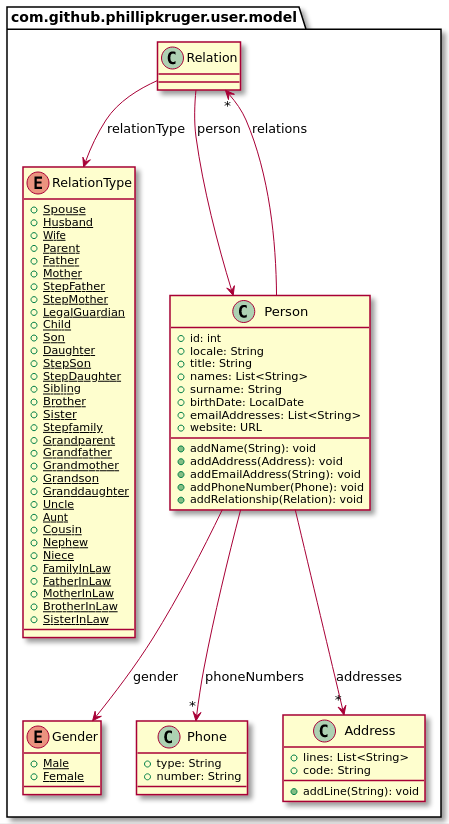
Now let’s assume that PersonService makes a call to a database or some other storage to get the data. We can now inject the context object to get
details on the request, and optimise our call:
@ApplicationScoped
public class PersonService {
@Inject Context context;
public Person getPerson(int id){
// Use context to get more information on the query
// Let's print out the context here and see what we have
System.out.println(context);
// Get the person from the datastore here.
}
}Let’s do a Query to get the name and surname of Person 1:
{
person(id:1){
names
surname
}
}So what can you get from context ?
There are a few things we can get:
executionId = 30337360
request = {"query":"{\n person(id:1){\n names\n surname\n }\n}","variables":null}
operationName = null
operationTypes = [Query]
parentTypeName = Query
variables = null
query = {
person(id:1){
names
surname
}
},
fieldName = person
selectedFields = ["names","surname"]
source = null
arguments = {id=1}
path = /personWhat we probably want to know is which fields have been requested, so that we can do a better database query.
So the fieldName (person) and the selectedFields (names,surname) is what we need.
A more complex GraphQL Request, will then lead to a more complex datasource query, example, if we want to know the relationships we would do:
{
person(id:1){
names
surname
relations{
relationType
person{
names
surname
}
}
}
}That will give us this in the Context selectedFields:
[
"names",
"surname",
{
"relations":[
{
"relationType":[
]
},
{
"person":[
"names",
"surname"
]
}
]
}
]Context in source methods
Let’s add a field to person using @Source and see what the context can give us then. First we will add a service that fetches the exchange rate from an api (exchangeratesapi.io). This allows us to add the exchange rate for that person against some currency.
In Java we add this Source method:
public ExchangeRate getExchangeRate(@Source Person person, CurencyCode against){
Map<CurencyCode, Double> map = exchangeRateService.getExchangeRates(against);
Double rate = map.get(person.curencyCode);
return new ExchangeRate(person.curencyCode, against, rate);
}Now we can query that (ExchangeRate) field:
{
person(id:1){
names
surname
exchangeRate(against:GBP){
rate
}
}
}When we Inject and print the context in the ExchangeRateService we now get:
executionId = 17333236733
request = {"query":"{\n person(id:1){\n names\n surname\n exchangeRate(against:GBP){\n rate\n }\n }\n}","variables":null}
operationName = null
operationTypes = [Query]
parentTypeName = Person
variables = null
query = {
person(id:1){
names
surname
exchangeRate(against:GBP){
rate
}
}
}
fieldName = exchangeRate
selectedFields = ["rate"]
source = com.github.phillipkruger.user.model.Person@7929ad0a
arguments = {against=GBP}
fieldName = exchangeRate
path = /person/exchangeRateNote that the fieldName is now exchangeRate and the selectedFields is ["rate"]. You will also note that the source field is populated with the person.
Cache
Another question that comes up regularly is how can you cache your endpoint results. As an example, let’s say the Exchange Rate information can be updated daily, so we do not want to make a call to the exchangeratesapi.io for every call.
You can just use the caching that comes with Quarkus! Simply include the cache extension:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-cache</artifactId>
</dependency>And add the @CacheResult annotation to your method:
@CacheResult(cacheName = "exchange-rate-cache")
public ExchangeRate getExchangeRate(@Source Person person, CurencyCode against){
Map<CurencyCode, Double> map = exchangeRateService.getExchangeRates(against);
Double rate = map.get(person.curencyCode);
return new ExchangeRate(person.curencyCode, against, rate);
}Read more about caching in Quarkus here: quarkus.io/guides/cache
Asynchronous
Now, let’s add another service that returns the weather conditions for a city:
@GraphQLApi
public class TravelEndpoint {
@Inject
WeatherService weatherService;
@Query
public Weather getWeather(String city){
return weatherService.getWeather(city);
}
}Let’s say this person is traveling to London, you can now do something like this:
{
person(id:1){
names
surname
exchangeRate(against:GBP){
rate
}
}
weather(city:"London"){
description
min
max
}
}At the moment the person and weather query will execute sequentially, and there is no real reason that this should be the case. We can get the weather at the same time that we get the person.
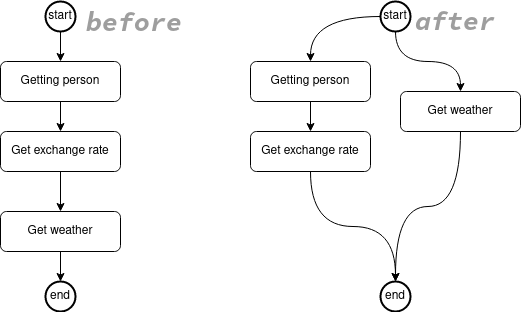
Let’s change the java code:
@Query
public CompletableFuture<Person> getPerson(int id){
return CompletableFuture.supplyAsync(() -> personService.getPerson(id));
}and
@Query
public CompletableFuture<Weather> getWeather(String city){
return weatherService.getWeather(city);
}Now person and weather are being fetched concurrently.
Let’s say this person actually wants to travel to London and New York, we can do something like this:
{
person(id:1){
names
surname
gbp:exchangeRate(against:GBP){
rate
}
usd:exchangeRate(against:USD){
rate
}
}
uk:weather(city:"London"){
description
min
max
}
us:weather(city:"New York"){
description
min
max
}
}We can now change the code to also fetch the exchange rates concurrently:
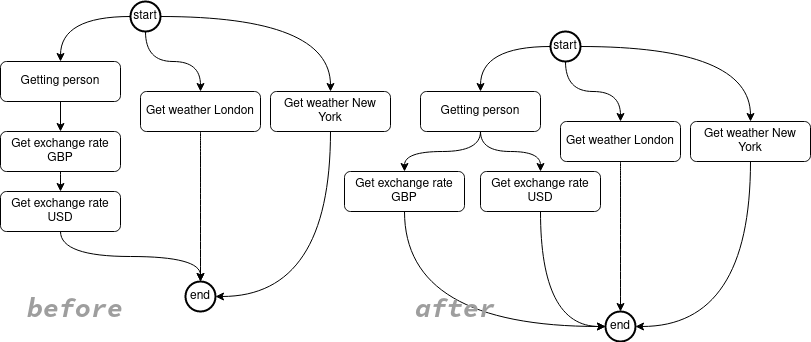
public CompletableFuture<ExchangeRate> getExchangeRate(@Source Person person, CurencyCode against){
return CompletableFuture.supplyAsync(() -> exchangeRateService.getExchangeRate(against,person.curencyCode));
}Batch
If you want to get ALL people, and you are including a field (like exchangeRate) with a Source method, it means that for every person, we will call the getExchangeRate method. Depending on the number of people, that could be a lot of calls. So you might rather want to do a batch source method.
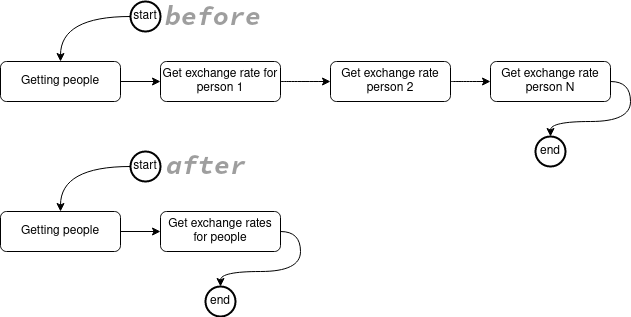
This will allow you to get all the people in one method and do one call to get their exchange rates.
So, let’s change the getExchangeRate method to take a List of person and return a List of ExchangeRate:
public List<ExchangeRate> getExchangeRate(@Source List<Person> people, CurencyCode against){
Map<CurencyCode, Double> map = exchangeRateService.getExchangeRates(against);
List<ExchangeRate> rates = new ArrayList<>();
for(Person person : people){
Double rate = map.get(person.curencyCode);
rates.add(new ExchangeRate(person.curencyCode, against, rate));
}
return rates;
}
Above will still work on getPerson method where there is only one person.
|
Doing a query on all people:
{
people{
names
surname
exchangeRate(against:GBP){
rate
}
}
}This will call the getExchangeRate method with all people.
Generics
It’s the year 2050 and we need to extend our travel service to also cater for aliens. Let’s add a generic Being type:
public class Being<T> {
private T being;
public Being() {
}
public Being(T being) {
this.being = being;
}
public T getBeing() {
return being;
}
public void setBeing(T being) {
this.being = being;
}
}And now change the Endpoint to allow people and alien queries:
@Query
public Being<Person> getPerson(int id){
return new Being<>(personService.getPerson(id));
}
@Query
public Being<Alien> getAlien(int id){
return new Being<>(alienService.getAlien(id));
}We can then query both human and alien beings:
{
person(id:1){
being{
names
surname
}
}
alien(id:1){
being{
type
from
}
}
}Events and custom execution
Events are used internally when you enable integration with MicroProfile Metrics, MicroProfile OpenTracing and Bean Validation, but you can also take part in these events.
These are all CDI Events and can be used with the @Observes annotation.
While building the schema
When we scan the classpath for annotations and types, we build up a model of all the operations. You can manipulate this model by taking part in the create operation event:
public Operation createOperation(@Observes Operation operation) {
// Here manipulate operation
return operation;
}Just before the final schema is built, after scanning all annotations and after the above event, you can take part and contribute to the schema:
This exposes the underlying graphql-java implementation details, and can be useful when you want to do things that are not yet implemented in SmallRye GraphQL, like subscriptions for instance:
public GraphQLSchema.Builder beforeSchemaBuild(@Observes GraphQLSchema.Builder builder) {
// Here add you own, in example a subscription
return builder;
}While running a request
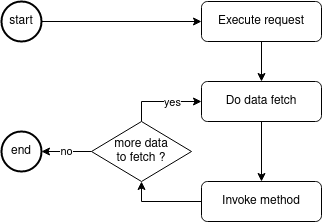
In this example request:
{
person(id:1){
names
surname
exchangeRate(against:USD){
rate
base
}
}
}the request flow is as follows:
-
The Execution service gets the request.
-
The person is being fetched with a
datafetcher. -
Your CDI bean (
@GraphQLApi) method (getPerson) is being invoked. -
The exchange rate is being fetched, passing the above person as an argument.
-
Your CDI bean (
@GraphQLApi) method (getExchangeRate) is being invoked. -
Data is being returned.
You can receive events on all of these points:
public void beforeExecute(@Observes @BeforeExecute Context context) {
System.err.println(">>>>> Received beforeExecute event [" + context.getQuery() + "]");
}
public void beforeDataFetch(@Observes @BeforeDataFetch Context context) {
System.err.println(">>>>> Received beforeDataFetch event [" + context.getQuery() + "]");
}
public void beforeInvoke(@Observes InvokeInfo invokeInfo) {
System.err.println(">>>>> Received beforeInvoke event [" + invokeInfo.getOperationMethod().getName() + "]");
}
public void afterDataFetch(@Observes @AfterDataFetch Context context) {
System.err.println(">>>>> Received afterDataFetch event [" + context.getQuery() + "]");
}
public void afterExecute(@Observes @AfterExecute Context context) {
System.err.println(">>>>> Received afterExecute event [" + context.getQuery() + "]");
}You can also get events when an error occurs:
public void errorExecute(@Observes @ErrorExecute ErrorInfo errorInfo) {
System.err.println(">>>>> Received errorExecute event [" + errorInfo.getT() + "]");
}
public void errorDataFetch(@Observes @ErrorDataFetch ErrorInfo errorInfo) {
System.err.println(">>>>> Received errorDataFetch event [" + errorInfo.getT() + "]");
}Using the Execution Service directly
The default assumed behavior is to interact with your endpoint via HTTP, you can however inject the ExecutionService yourself and execute requests.
As an example, lets do a request that gets all the names of all the people on startup:
{
people{
names
}
}We can now do this:
@ApplicationScoped
public class StartupService {
@Inject ExecutionService executionService;
public void init(@Observes StartupEvent event){
JsonObjectBuilder builder = Json.createObjectBuilder();
builder.add("query", ALL_NAMES);
JsonObject request = builder.build();
JsonObject response = executionService.execute(request);
System.err.println(">>>>> " + response);
}
private static final String ALL_NAMES = "{\n" +
"people{\n" +
" names\n" +
" }\n" +
"}";
}Transformation and mapping
By default, Date and Number values can be transformed using JsonB Formats
public class Person {
public String name;
@JsonbDateFormat("dd.MM.yyyy")
private Date birthDate;
@JsonbNumberFormat("#0.00")
public BigDecimal salary;
}MicroProfile GraphQL Specification maps the relevant Java types to a GraphQL Scalar. You can change the mapping of an existing field to map to another Scalar type like this:
@ToScalar(Scalar.Int.class)
Long id; // This usually maps to BigIntegerIn the GraphQL Schema this will now map to an int.
You can also add an Object that should transform to a Scalar Type and not a complex object, example you might have an Email Object, but do not want to use a complex type in GraphQL, and rather map this to a String:
To do this your Email POJO needs to implement the toString method and have a constructor that takes a String, or a static Email fromString(String s) method, or a setValue(String value) method.
public class Email {
private String value;
public Email() {
}
public Email(String value) {
this.value = value;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return value;
}
}You can then use this as a field on your Response and add the @ToScalar annotation, i.e. person:
@ToScalar(Scalar.String.class)
Email email; // This usually maps to a complex objectBuild tools
Example, in maven you can add this to your pom.xml:
<plugin>
<artifactId>smallrye-graphql-maven-plugin</artifactId>
<groupId>io.smallrye</groupId>
<executions>
<execution>
<goals>
<goal>generate-schema</goal>
</goals>
</execution>
</executions>
</plugin>and the generated schema will be stored in target/generated/.