VCStream: a new messaging platform for DECATHLON’s Value Chain, built on Quarkus.
By

DECATHLON is a French retailer, dedicated to sport products, with more than 1800 stores worldwide. At DECATHLON, we are convinced that sport is a source of well-being.
VCStream is a new platform for streaming data across the Value Chain of DECATHLON. It allows streaming data in and out of the Value Chain, what we called the inbound (from external systems to the Value Chain) and the outbound (from the Value Chain to external systems) processes.
VCStream slogan: “One platform to connect them all”.
VCStream offers connectors to easily stream data from incoming Kafka topics to existing Value Chain ERP modules, and from these ERP modules to outgoing Kafka topics and object store.
VCStream leverages the Quarkus framework, and Kubernetes, to offer a resilient and performant platform that meets security and reliability requirements of DECATHLON Value Chain.
Age Of Access Accelerator (AoAA) is the team behind the VCStream platform. We’re a small team of three Developers, a DevOps, a Product Owner and an Enterprise Architect; let’s not forget our team Leader of course (that also develops when he finds some time to do so).
The Challenge
The Value Chain IT department faces a major problem around data exposure and consumption to and from the other departments of DECATHLON. The business was scaling steadily, driving significantly higher levels of resource consumption, capacity demands, and event data in real time. We realized that our system could not keep up.
The current usage of dedicated servers was leading to an increase of resource waste. The department’s reliance on legacy workflows and ERP ecosystems resulted in significant productivity bottlenecks. Thinking about data as streams is a popular approach nowadays. In many cases, it allows to build a data engineering architecture in a more efficient way than the classic “data as a state” one. But to support the streaming data paradigm, we need to use additional technologies. One of the most popular tools for working with streaming data is Apache Kafka, and DECATHLON decided to invest heavily in it.
The quality of data produced to VCStream is extremely important to us, especially because we are running VCStream at scale. Data produced by one team can and will be consumed by many different applications within DECATHLON. The lack of data quality can have a huge impact on downstream consumers.
Prior to the VCStream platform, the Value Chain was challenged with:
-
Data standardization: data was exposed in a non-uniform manner and without standards.
-
Time to market: exposing new data would take time as we relied on manual scheduling via legacy tools.
-
Consuming data in real time: as opposed to the current batch mode usage.
-
Scalability and Resilience: huge volumes of data are processed, and the legacy system is fragile.
We knew our Value Chain needed a platform to modernize our data exchange: a product that could enable data access, efficient data integration, container adoption, and developer velocity at scale.
"Almost every weekend is the biggest weekend we’ve ever had in the Value Chain! our system has just become unstable. We can not deal with application deployment in the old way.” - is the observation from many of us.
Why Quarkus?
To implement VCStream, our team evaluated Spring Boot, Micronaut and Quarkus. As none has real experience with Micronaut, we quickly leave it out.
We selected Quarkus based on the followings criterias:
-
The team was interested to learn a new framework
-
Microprofile reactive messaging seems very interesting and a neat API to implement messaging only microservices which is what we needed primarily.
-
Performance is at the heart of Quarkus, and more importantly, low resource consumption (both CPU and memory) which is important as we plan to deploy to the cloud, and have some ecological sensitivity on the team.
-
All the containers, Kubernetes and cloud ready functionalities that we need to properly implement a resilient application on GKE are there.
Lastly, we have a Quarkus contributor on the team which allows us to have a deep understanding of the framework, and a unique contact within the community.
Speaking of the community, the Quarkus one is very active and welcoming. This was one of the most important criteria for us.
Of course, we performed some proof of concepts with all the team members, compared implementations, and decided together what the best choice would be in our context.
During these proof of concepts, we particularly enjoyed the fact that the Quarkus learning curve was very rapid and easier than what we first thought. Newcomers have become comfortable with Quarkus in less than a week, and all the developer oriented functionalities (live reload FTW!) have really empowered them to be more productive on their day to day tasks.
Our commitment
Within DECATHLON, there weren’t many projects that used Quarkus, unlike Spring Boot, which has already been proven, and there were several developers who are familiar with it.
Quarkus' position in our current TechRadar (trial) has not necessarily helped us to weigh our usage of it. The few developers with whom we had discussions on the use of Quarkus had expressed some reservations about the notion of performance that was put forward by the framework.
Making objective choices (for the company and for developers who have a passion for the framework), on a new framework for our company was very difficult! We cannot rely solely on the advice of the Quarkus expert on our team to make the choice. This is the reason why we started with a POC, with the objective that if we would face some impossible situation, we would go back to Spring Boot without hesitation! Knowing this POC would still cost us in a difficult economic context that everyone knows.
Fortunately, the project went well, and we now have successfully deployed it in production and connected many ERP modules with external IT systems thanks to VCStream.
VCStream architecture
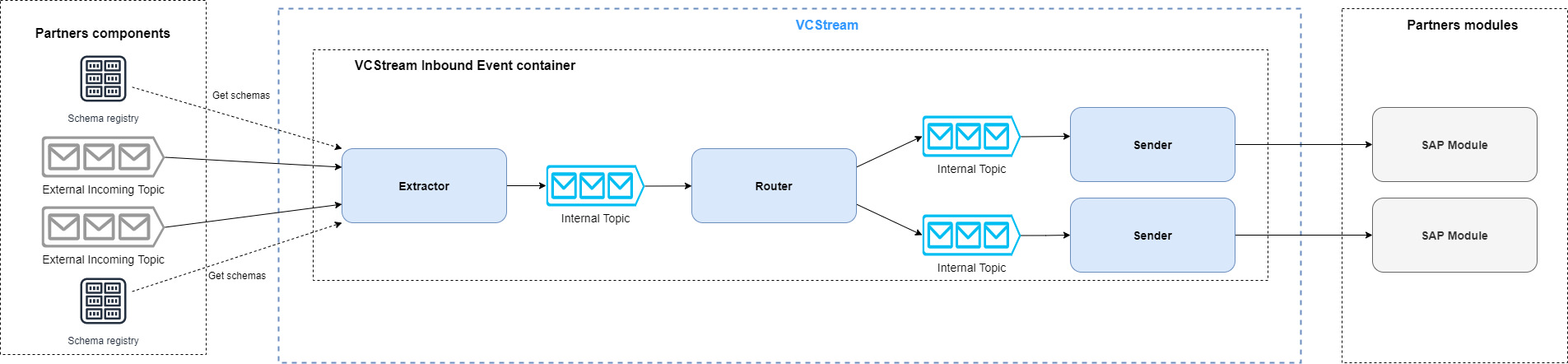
This is a simplified view of the VCStream inbound process architecture: the extractor connects to multiple Kafka brokers and consumes messages from multiple topics in real time. These messages are then converted to JSON, routed and sent to multiple ERP modules (one message can go to one or more ERP modules). There is one sender instance per ERP module.
Currently, we extract from 6 topics and send to 3 ERP modules but we foresee to consume from up to 25 different topics at the end of 2022.
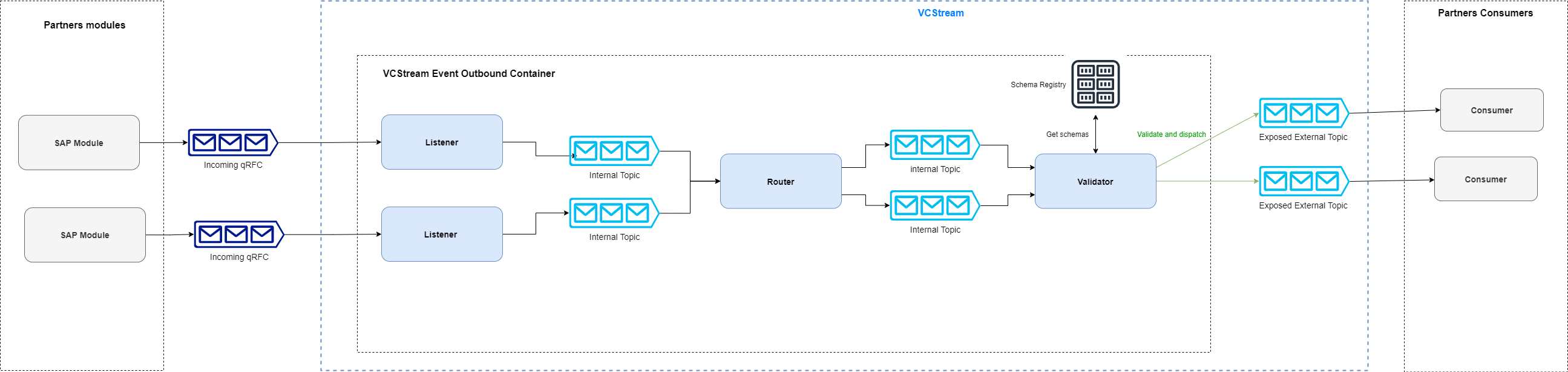
This is a simplified view of the VCStream outbound process architecture: the listener watches for JSON messages from an ERP module. These messages are routed, then sent to the validator that validates them, converted to AVRO format, and exposed in dedicated topics. There is one listener instance per ERP module.
Currently we receive messages from 4 ERP modules and expose 6 topics but we foresee to expose up to 25 topics at the end of 2022.
Embracing Quarkus
Here are testimonials of the usage of Quarkus from the members of the VCStream platform development team.
Fawaz Paraïso - Team Leader
As a developer and the team leader, I had to make my own beliefs about choosing to use Quarkus for our platform implementation. Our technological choice must be consistent with DECATHLON’s development strategies.
In comparison with Spring Boot which has already established itself, Quarkus is a new framework in the Java ecosystem. Beyond these considerations (new), our team should give a concrete opinion of what Quarkus could offer. Getting started with Quarkus was easy for me, it may be related to my experience as a senior developer. After a week of development with Quarkus, I was able to regain the same level of productivity as when I was developing with Spring Boot. For the implementation of our platform, SmallRye Reactive Messaging was newer to me and met the architectural constraints of our platform. Our POC was successful with results (simplicity, performance, resilience) above our expectations. Despite the positive results obtained, I did not want to stop there. I wanted to get another perspective from a junior developer who, like me, had never used Quarkus.
The arrival of a new collaborator with a junior profile in our team who does not know our project, neither Quarkus, provided me with other elements of answers on how to get started with Quarkus. He made his first contributions to our repositories in the first week. This collaborator’s experience with using Quarkus has definitely assured me of how easily a junior developer can get started with Quarkus.
Thomas Dangleterre - Junior Developer
I joined the team 4 months after the project started. I have been recruited to step in as a junior Java Software Developer. It was the first time I had to deal with microservices architecture and I just had a small experience of the cloud. I really enjoy the hot reload feature on Quarkus it is something that I was not used to from my previous missions on legacy applications. I like how it is easy to interact with Kafka thanks to the abstraction offered by SmallRye Reactive Messaging.
It was pretty easy to adapt myself to Quarkus as I knowed Spring Boot a bit, and there are a lot of similarities. I also found Quarkus' documentation very clear and I’m really looking forward to keep learning more about Quarkus.
Victor Gallet - Senior Developer and Kafka Expert
When I joined the team, around ten microservices had already been deployed with Quarkus. I had not yet had the opportunity to play with Quarkus, I had just seen presentations at a meetup and the framework interested me. Having worked since the beginning of my career with the Spring framework, I wanted to discover the big differences compared to Quarkus. Despite utility classes and different CDI annotations, I was able to get up and running with Quarkus very quickly. The Quarkus Guides have been a huge help as they focus on one topic and get straight to the point. For example, since our microservices communicate exclusively with Apache Kafka, the Quarkus integration guide with Apache Kafka allowed me to immediately understand the concepts and our different components.
Compared to the dependency injection and the implementation provided by Quarkus (ArC), I had no problem navigating it. The concepts are standard and I only had to discover some new annotations like @ApplicationScoped and @Singleton to name just the most used ones.
To sum up, here are the points that I really enjoyed working with Quarkus:
The live reload
One feature that I really liked is the live reload. Starting my day in the morning, I would launch the application I needed to work on, and no longer have to worry about restarting it during the day. A very practical feature coupled with a very short start-up time!
Unified configuration and profile management
With this simple little bit of configuration
greeting.message=hello %dev.greeting.message=hey %test.greeting.message=hi
It allows the greeting.message property to be overridden when launching the application locally with the value “hey” and for tests with the value ”hi”. This is very convenient and greatly simplifies configuration management for testing.
The support
I already mentioned it above, but the documentation is very clear, and the guides allow you to discover a functionality, a use of Quarkus in a simple and fast way. I was also pleasantly surprised at the responsiveness and support of the Quarkus community within their Zulip chat. A big thank you to Clément Escoffier who helped us improve our applications, and personally helped me to do my first open source contribution to the SmallRye Reactive Messaging project.
One point of attention that I have come up against with my liability as a Spring developer is that Quarkus takes a number of actions during build to reduce startup time and its memory footprint. Having wanted to have a dynamic behavior in my application, I used the annotation @IfBuildProperty to select the appropriate bean but, as its name suggests, the bean will be selected during the build and the alternatives will not be available at runtime.
Finally, to end my feedback, I regret not having faced the construction of a native image. But our project has opted for the deployment of containers within a Kubernetes cluster, which is what Quarkus is designed for.
Loïc Mathieu - Senior Developer
I’m a regular Quarkus committer and knows very well Quarkus before I joined the team. So I will give a very narrow testimonial, on a very specific feature we used and that I very love.
Reactive programming is at the heart of Quarkus, and reactive messaging, as its name implies, is a reactive framework.
When you need to consume or produce a message, you can simply use the payload as method parameter or return type. But when you need to implement asynchronous processing or complex logic on a stream of messages, you’ll need to use Mutiny instead of directly using your payload type. Mutiny is a set of reactive types and operators. It allows to express a set of transformations on a stream of items and follows the reactive stream standard.
One of our needs was to group incoming messages into batches, as sending a message to an ERP module has a cost, and they fear receiving millions of messages per day. So we need to group them by type, then by batch of 50, and emit at least one batch per minute to avoid adding too much delay to the message delivery.
To implement this, we prototype the usage of Kafka Stream, but it adds some complexity to our current technical stack as we didn’t use it already, and it has some grouping limitations (grouping by size is not provided out of the box by the framework).
So we decided to simply use what we already have in our toolbox, Mutiny, and the code we implement is really readable for such a complex task, and we have been very happy with it since.
@Incoming("in")
@Outgoing("group-out")
public Multi<Message<List<ErpMessage>>> group(Multi<KafkaRecord<String, RawMessage>> events) { (1)
return events
.group().by(record -> record.getPayload().type) (2)
.flatMap(group -> group.group().intoLists().of(size, duration)) (3)
.filter(group -> !group.isEmpty()) (4)
.flatMap(groupedMultis -> {
List<ErpMessage> erpMsg = groupedMultis.stream() (5)
.map(record -> toErpMessage(record))
.collect(Collectors.toList());
return Multi.createFrom().item(KafkaRecord.of((String) null, erpMsg)); (6)
});
}
-
The method takes a stream of Kafka messages.
-
First, we group by payload type.
-
Then, we group by batch of size messages with a max duration of duration.
-
Then, we remove empty batches.
-
Then, we map each batch of message to a new format.
-
Then we return a Kafka message with the batch in it.
Pretty straightforward, right?
Looking forward
Performance was at the heart of the design and implementation of VCStream, we perform regular load tests and run regular crisis scenarios (we simulate keeping up with a high number of messages waiting in the broker by manipulating topics offset).
Each time we encounter performance bottlenecks or regressions, we discuss them with the Quarkus community and have very prompt feedback. All issues were resolved quickly and the performance and resilience of our platform kept improving over time.
We deployed on the cloud, which implies direct cost we can measure easily. Even if today our platform is not yet used a lot in production (only half of the currently deployed topics are really used), we foreseen a need to scale to up to 1.5 million messages per minute at the end of 2022, and to connect to more than twice the current number of ERP modules. So the level of performance and the resources needed to achieve it is very important.
The good news is: we are not afraid of this as the platform in its current state can already sustain a high number of messages per minute. We benchmark our platform on our crisis scenario to up to 500 thousand messages per minute per instance even with Kafka clients favoring consistency
And thanks to Quarkus, a single instance of a component uses as less as 0.5 CPU and 512MB or memory (heap size is around 120MB), we could go less as all the CPU and memory is not used, but it’s already very little so we prefer to be conservative on this. Oh, yes, and this is on Java 16 and using the JVM.
To put it in another words, we achieve a 1 millions messages per minutes throughput per CPU per GB of memory on a real world streaming application thanks to Quarkus and MicroProfile reactive messaging. This is quite an impressive throughput density, and we are very happy with it.
A few last words, we would like to especially thank the Quarkus community for helping us, answering our questions again and again, improving Quarkus on each release and for the really good job they made with Quarkus and the fabulous MicroProfile Reactive Messaging framework! Thank you all, you’re amazing!
This article has been written and proofread by all the members of the Age of Access Accelerator team.