Using LangChain4j to analyze PDF documents
By

In my consulting work, clients frequently present us with challenging problems that require innovative solutions. Recently, we were tasked with extracting structured metadata from PDF documents through automated analysis. Below, I’ll share a simplified version of this real-world challenge and how we approached it.
Use Case
Our client receives compressed archives (.zip files) containing up to hundreds of portable document format (PDF) lease documents that need review. Each document contains property lease details that must be validated for accuracy. The review process involves checking various business rules - for example, identifying leases with terms shorter than 2 years. Currently, this document validation is done manually, which is time-consuming. The client wants to automate and streamline this review workflow to improve efficiency.
Some complications with these lease documents are:
-
The documents are not in a standard format so each lease may be written in a different way by a different property manager.
-
The documents may be scanned, so the text is sometimes human writing and not typewritten.
-
The documents may contain multiple pages, which are not always in the same order.
-
The lease terms may not be an actual date but written as "Expires five years from the start date" or "Expires on the anniversary of the start date".
-
Metadata such as acreage and tax parcel information is needed by our client to validate the lease details.
You can understand why this is time consuming for a human to review and validate the documents.
Our Solution
After consulting with Dmytro Liubarskyi and collaborating with the Quarkus team, we implemented a solution using LangChain4j for document metadata extraction. We chose Google Gemini as our Large Language Model (LLM) since it excels at PDF analysis through its built-in Optical Character Recognition (OCR) capabilities, enabling accurate text extraction from both digital and scanned documents.
Technical Details
The application is built using:
-
Quarkus - A Kubernetes-native Java framework
-
LangChain4j - Java bindings for LangChain to interact with LLMs
-
Google Gemini AI - For PDF document analysis and information extraction
-
Quarkus REST - For handling multipart file uploads
-
HTML/JavaScript frontend - Simple UI for file upload and results display
The backend processes the PDF through these steps:
-
Accepts PDF upload via multipart form data
-
Converts PDF content to base64 encoding
-
Sends to Gemini AI with a structured JSON schema for response formatting
-
Returns parsed lease information in a standardized format
-
Displays results in a tabular format on the web interface
The main components are:
-
LeaseAnalyzerResource- REST endpoint for PDF analysis -
LeaseReport- Data structure for lease information -
Web interface for file upload and results display
How it works
First we need a Google Gemini API key. You can get one for free, see more details here: Gemini API Key Documentation.
export QUARKUS_LANGCHAIN4J_AI_GEMINI_API_KEY=<your-google-ai-gemini-api-key>Next we need to install the LangChain4j dependencies:
<dependency>
<groupId>io.quarkiverse.langchain4j</groupId>
<artifactId>quarkus-langchain4j-ai-gemini</artifactId>
<version>0.25.0</version>
</dependency>Configure Gemini LLM
Next we need to wire up the Gemini LLM to the application (using your Google AI Gemini API key).
quarkus.langchain4j.ai.gemini.chat-model.model-id=gemini-2.0-flash
quarkus.langchain4j.log-requests=true
quarkus.langchain4j.log-responses=trueLogging the request and response is optional but can be helpful for debugging.
Register the AI service
We must register the AI service to use the LeaseAnalyzer interface.
import dev.langchain4j.data.pdf.PdfFile;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.PdfUrl;
import io.quarkiverse.langchain4j.RegisterAiService;
@RegisterAiService(chatMemoryProviderSupplier = RegisterAiService.NoChatMemoryProviderSupplier.class)
public interface LeaseAnalyzer {
@UserMessage("Analyze the given document")
LeaseReport analyze(@PdfUrl PdfFile pdfFile);
}Define your data structure
Now we need to model the data structure for the lease information that we want the LLM to extract from any lease document. You can customize these fields based on the information you need from the PDF documents but in our use case below we are extracting the following information:
public record LeaseReport(
LocalDate agreementDate,
LocalDate termStartDate,
LocalDate termEndDate,
LocalDate developmentTermEndDate,
String landlordName,
String tenantName,
String taxParcelId,
BigDecimal acres,
Boolean exclusiveRights) {
}Create the REST endpoint
Lastly, we need to create a LeaseAnalyzerResource class that will use the LLM to extract the lease information from the PDF document.
@Inject
LeaseAnalyzer analyzer;
@PUT
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Produces(MediaType.TEXT_PLAIN)
public String upload(@RestForm("file") FileUpload fileUploadRequest) {
final String fileName = fileUploadRequest.fileName();
log.infof("Uploading file: %s", fileName);
try {
// Convert input stream to byte array for processing
byte[] fileBytes = Files.readAllBytes(fileUploadRequest.filePath());
// Encode PDF content to base64 for transmission
String documentEncoded = Base64.getEncoder().encodeToString(fileBytes);
log.info("Google Gemini analyzing....");
long startTime = System.nanoTime();
LeaseReport result = analyzer.analyze(PdfFile.builder().base64Data(documentEncoded).build());
long endTime = System.nanoTime();
log.infof("Google Gemini analyzed in %.2f seconds: %s", (endTime - startTime) / 1_000_000_000.0, result);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}There is a simple HTML/JavaScript frontend that allows you to upload a PDF document and view the results. In the example below 3 different lease documents were uploaded and analyzed.
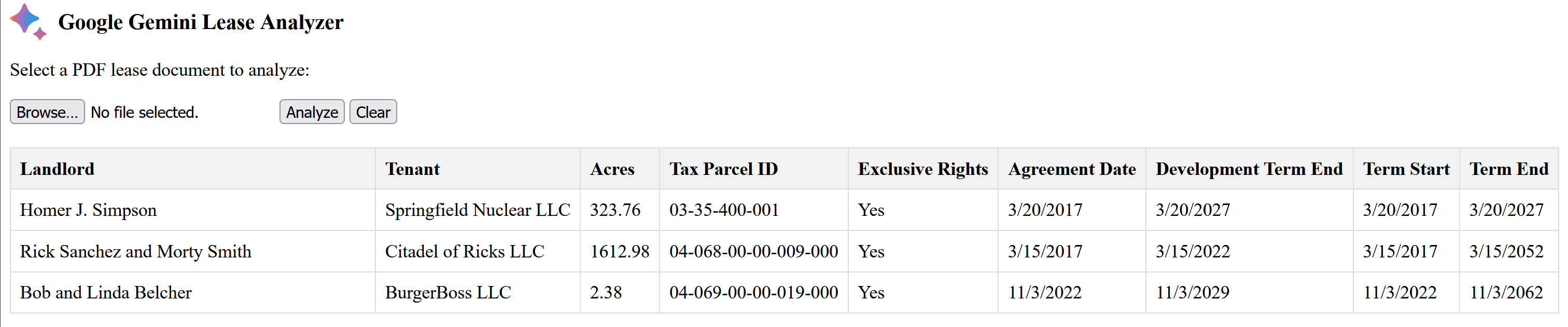
You can find the complete example code on GitHub.
Conclusion
This article demonstrated how LangChain4j and AI can be leveraged to automatically extract structured metadata from PDF documents. By implementing this solution, our client will significantly reduce manual document processing time, potentially saving thousands of work hours annually. The combination of LangChain4j and Google Gemini AI proves to be a powerful approach for automating document analysis workflows.