How Project Leyden brought a new perspective

This is a story about Project Leyden. And this is not a story about Project Leyden.
It is a story about how Project Leyden gave us a new perspective on how we think about startup performance in Quarkus, and, more broadly, in Java.
It is a story with flamegraphs.
Isn’t it the best kind of story?
Acknowledgments
I shared this journey with my dear colleague Georgios Andrianakis, who was also instrumental in making this happen. And this is exactly the kind of journey you want to share with someone.
How the story started
It all started with me complaining, more than once, that improving startup performance in Quarkus had become really hard. Startup was cluttered with class loading noise. Which means that every time you looked at a startup profile, you clicked on something suspicious and realized:
Oh well, that’s just us loading a class for the first time… bummer.
I’m a patient person. But you only get so many mouse clicks per day.
Then, one day, I took a shower, and I had this idea:
Isn’t Project Leyden supposed to improve the class loading story, among other things?
Maybe we could use it to get rid of the class loading noise and get a clearer picture of what’s really going on during startup?
As it turns out, this was a bit of a rabbit hole. Project Leyden delivered results that were far better than expected, and we ended up working with Georgios on integrating it tightly in Quarkus (you can see another blog post coming, right?).
But today, I promised you flamegraphs. I know you’re all excited about them. Let’s get to it!
Changing the perspective
We’ll explore this in more detail in a future blog post, but for now, suffice it to say that Project Leyden caches classes in a loaded and linked state, along with additional metadata such as method profiling information and, soon, compiled code.
In practice, Project Leyden improves Java startup performance by shifting expensive work, like class loading and linking, into a dedicated training phase. By capturing that state ahead of time, the application can skip much of the redundant setup normally performed at runtime.
In other words, if everything is recorded properly, class loading can be almost entirely taken out of the startup path.
And suddenly, you’re in brand-new territory: the Quarkus REST application you get from a simple quarkus create app starts in 130 milliseconds.
That’s already pretty good, right? But what’s even more interesting is that we were able to do much better (see you in the next blog post, remember?).
And this is where the perspective shifts significantly: when you start in ~ 100 milliseconds, every dozen milliseconds you save becomes a meaningful improvement. You can no longer afford to ignore a 5-millisecond cost.
I can hear someone in the room shouting:
Stop with the words! I want my flamegraphs!
Fine, fine.
How can we improve as an ecosystem?
One extremely important note before we begin: we’re not trying to criticize any library or framework here. We also found some low-hanging fruits in Quarkus itself, we’re all in the same boat here.
The goal of this blog post is to show how Project Leyden helped us uncover things that had been hidden for far too long. And hopefully, this will give other library and framework authors a few useful ideas, and ultimately help improve the Java ecosystem as a whole.
And in the worst case, at least you got your flamegraphs \o/.
Compatibility layers

Many libraries include compatibility layers to support multiple JDK versions. Typically, they rely on reflection to determine whether features like virtual threads are available.
In the Quarkus ecosystem, this is common in low-level libraries such as Netty or Vert.x. But in reality, we see this pattern everywhere.
We should avoid this. It has a cost, and that cost is paid at every single startup of every application using these libraries.
Multi-release JARs are not perfect. They’re harder to maintain, harder to test, and not always well supported by IDEs. But they do solve this problem. And I would argue that, as library and framework authors, it’s our responsibility to ensure the cost is paid once at build time, not at every application startup.
Together with Georgios, we decided to experiment with rewriting the bytecode of some of these libraries at build time to remove the reflective calls and replace them with direct invocations, when the application was targeting a Java version that supports the feature.
It’s a bit of a hack, and definitely not something we want to maintain long term, but it was a great way to validate the idea and score a few quick wins.
Reading annotations
This one isn’t new to us: one of the reasons we wrote Quarkus in the first place was to avoid reading annotations at runtime.
For most of our use cases, we can process annotations at build time and generate the necessary bytecode so there’s no need to inspect them at runtime. Jandex, our annotation indexer, is a fantastic tool for this, and we use it extensively in Quarkus. But… there are still cases where annotations are read at runtime, even in Quarkus.
Why is reading annotations so costly? Because parsing them has a cost. It happens the first time you try to access them at runtime, and the JDK then creates proxy instances to expose the annotation values.
Netty and marker annotations
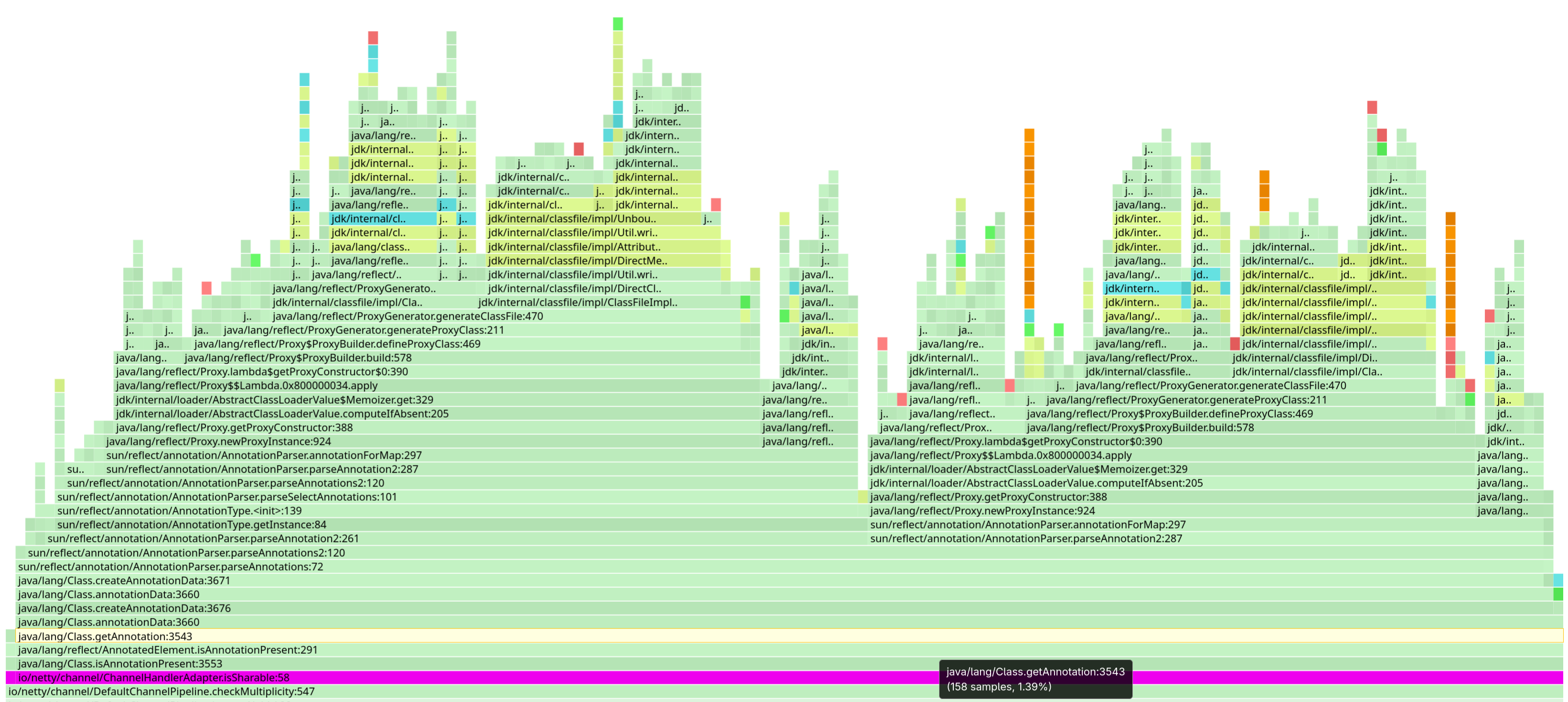
ChannelHandler is sharableThe Netty case is particularly interesting because it reads annotations to determine the capabilities of interface implementations.
For this kind of use case, we recommend using marker interfaces or methods instead of annotations.
Georgios once again resorted to bytecode rewriting to eliminate the annotation lookup. Again, this isn’t something we want to maintain in the long term.
Hibernate ORM
Hibernate ORM is also extremely interesting in this context.
The first important point is that, with Hibernate ORM, in Quarkus, we still build the metadata at runtime. That means we end up reading a lot of annotations at runtime. A long-term effort has already started to improve this situation, but it’s a significant undertaking and will take time before we can move metadata building to build time instead.
Let’s set that aside for now.
What’s also interesting is that Hibernate ORM collects metadata about its own annotations at runtime, both Hibernate-specific annotations and JPA annotations. And that’s a lot of annotations, and a lot of metadata to process.
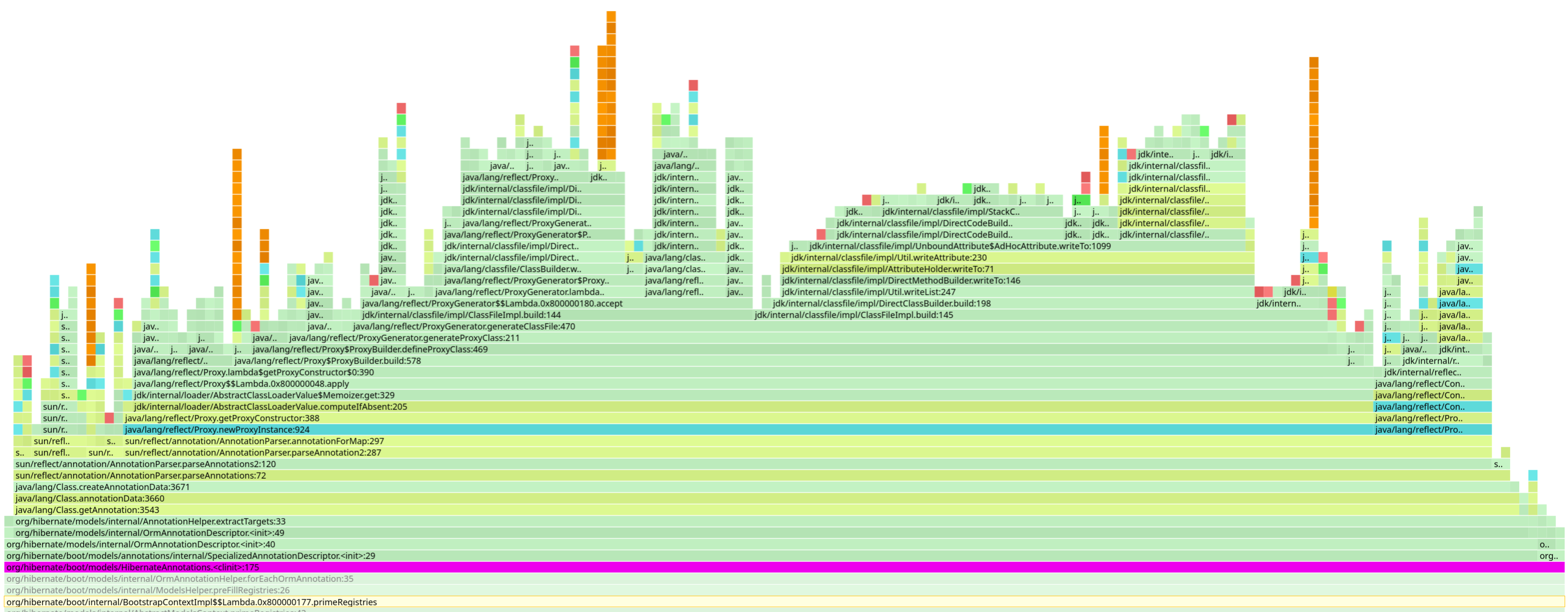
For example, for each JPA or Hibernate annotation, it determines the annotation target (class, method, field), or whether it is inherited.
In the end, this results in a substantial amount of annotation processing for something that changes very rarely.
I identified this issue some time ago, and our colleague Luca Molteni from the Hibernate team will be looking into it soon. We’re not yet sure how easy it will be to fix, but you get the idea. Whenever possible, this kind of metadata should be resolved once and for all. And you should be able to enforce its correctness with tests to ensure it remains accurate and up to date.
Hopefully, we’ll be able to improve this soon. And the nice part is that any improvement here will benefit all applications using Hibernate ORM, not just Quarkus applications.
The new cost of loading
When not using Leyden, you load a gazillion classes. JAR files are opened anyway, that’s "fine". Well, depending on your definition of "fine".
When using Leyden, you can reach a point where no classes are loaded at startup at all.
Which means that anything attempting to load something from the classpath will trigger JAR files to be opened (the first time they are accessed), and then read from disk.
And you can be sure that some resources will be loaded from your classpath:
-
ServiceLoaderservice files (the ones inMETA-INF/services/), used by the JDK and many libraries and frameworks to discover interface implementations; -
Configuration files;
-
And probably many other things.
Non-existing classes and resources
Why would you try to load a non-existing class? That’s a good question.
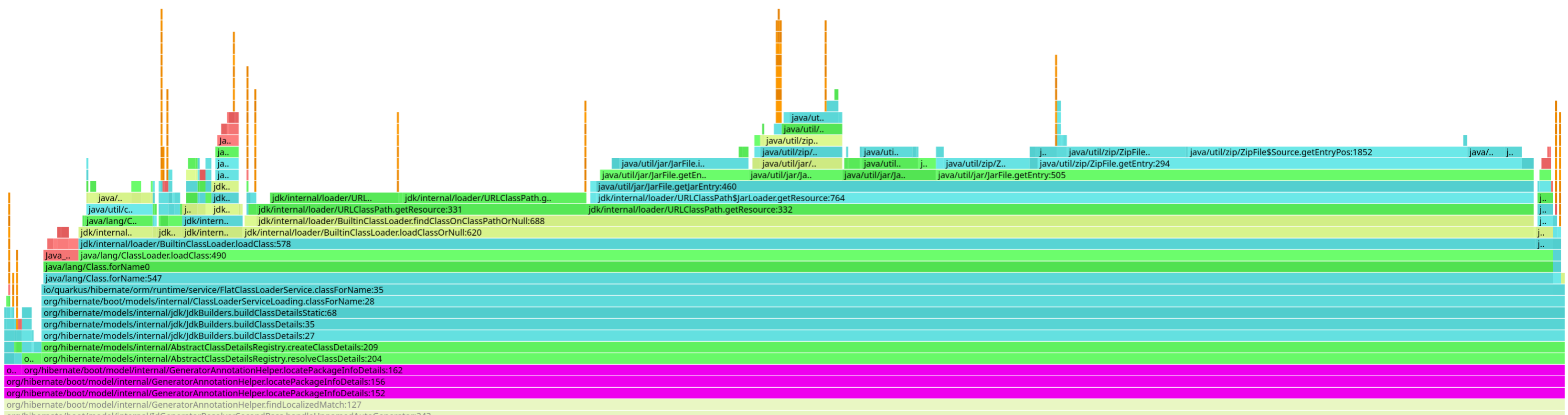
package-infoRemember package-info.java files?
Hibernate ORM, for instance, tries to load them to inspect package-level annotations.
In a lot of cases, these files don’t exist, and that’s perfectly normal.
Caching class loading is within the scope of Leyden, but Leyden does not cache negative lookups. Why? Because Leyden, while AOT, is still true Java. Java is a dynamic language: even if a class wasn’t present when you recorded the cache, it might be added later. Now, in practice, that’s often not the case, especially in Quarkus, where we assume a closed world, but Leyden cannot rely on that assumption.
In Quarkus, when using Leyden, we decided to generate empty package-info classes for all packages containing entities that don’t already have one.
This way, Hibernate ORM doesn’t have to attempt to load non-existing classes.

Another example is JBoss Logging internationalization: it attempts to load a class for the current locale, and if that class doesn’t exist, it falls back to the default class.
You see similar patterns with resources. An application might try to load a configuration file or a service descriptor that doesn’t exist. That’s perfectly normal, the only way to know it’s missing is to try.
In Quarkus, we have a few class loader tricks to mitigate this. But in the general case, you have to deal with it.
And here’s the catch: for all these cases, the runtime will walk the entire classpath (remember, it won’t find anything), trying to locate the class or resource. In doing so, it may open a large number of JAR files and read from them, just to conclude that the class or resource doesn’t exist.
Granted, it doesn’t read the entire JAR, each archive has an index, but still.
ServiceLoader
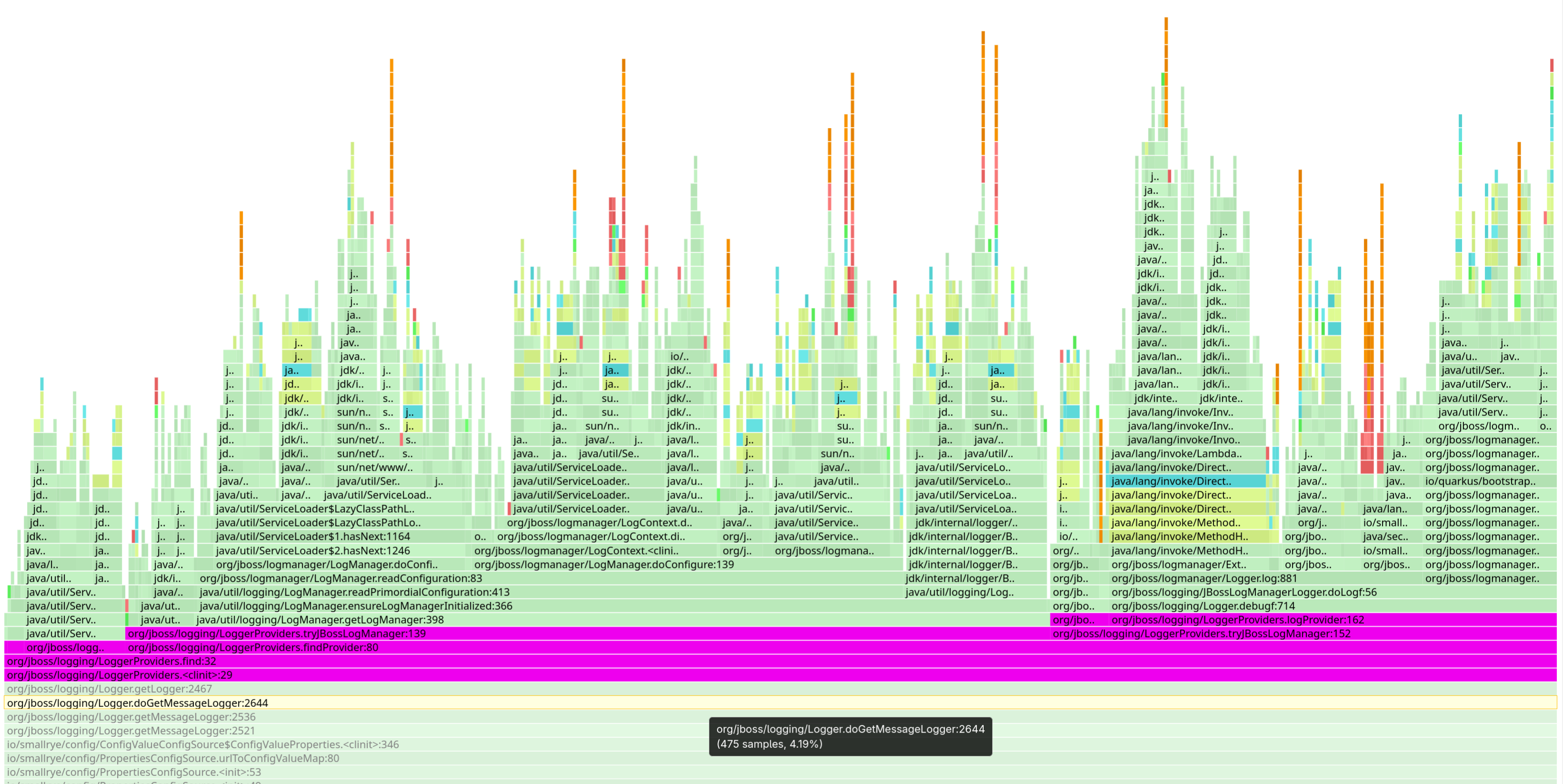
ServiceLoader stormLet’s look at the ServiceLoader case in more detail, it’s particularly interesting.
Once class loading is out of the picture, it becomes clear that a significant portion of startup time is spent loading service descriptors from JAR files. We managed to improve this for some services using a class loader trick, but that only works for services loaded through the thread context class loader. We don’t yet have a good solution for services loaded by the JDK class loaders. At least not for now.
We’ll go into more detail in the next blog post, where we’ll talk more about Project Leyden itself and how we integrated it into Quarkus. Stay tuned.
Some other fun facts
UUID generation
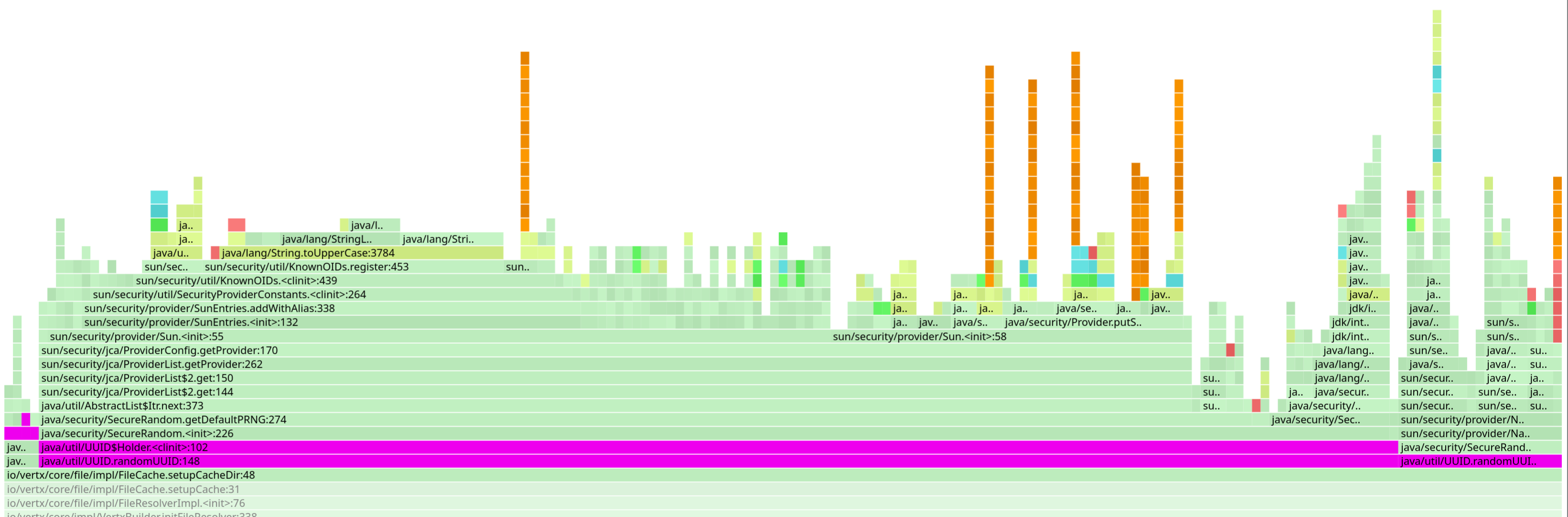
This one is easy: whenever you generate a UUID, the JDK will initialize a SecureRandom instance.
And initializing a SecureRandom instance doesn’t come for free, oh no.
Sure, if your application ends up needing a SecureRandom anyway, you don’t care.
But if it doesn’t, having your favorite framework generate UUIDs for internal use is not ideal.
|
Obviously, if your application genuinely needs |
BigDecimal
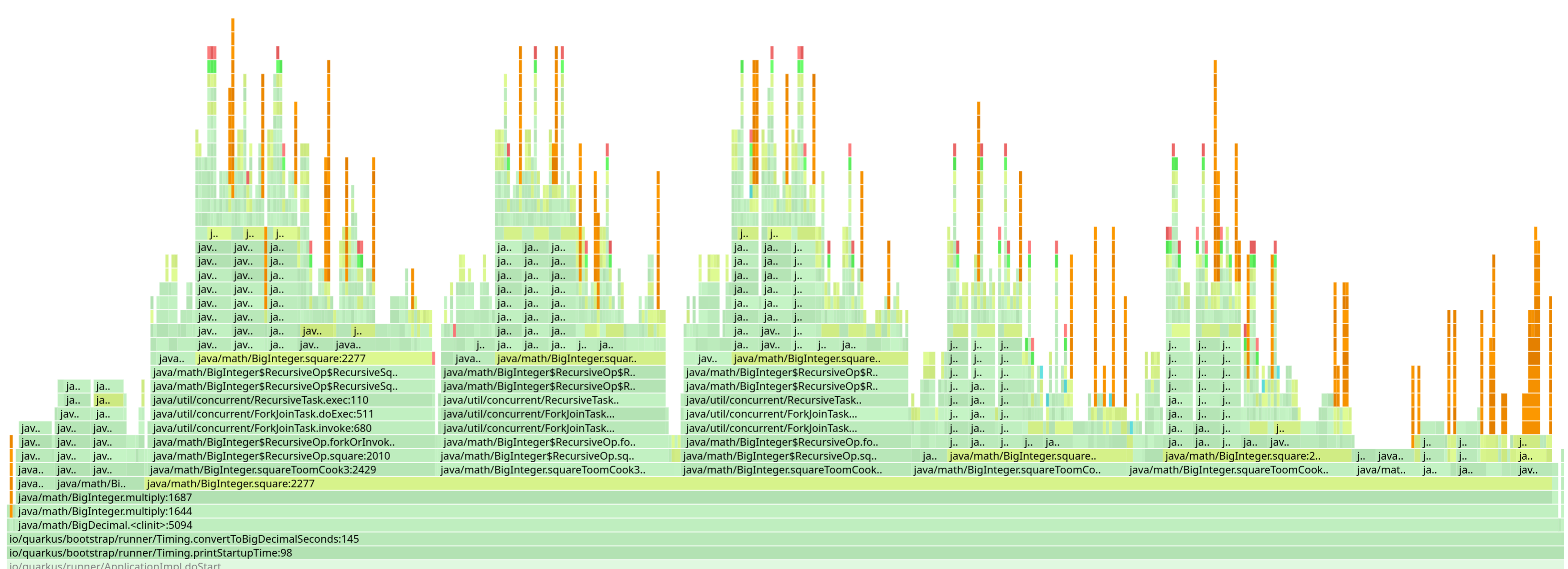
BigDecimalIn the same vein, the BigDecimal class has a static initializer that actually performs a fair amount of work.
Initializing BigDecimal can take a noticeable amount of time.
We stumbled upon this because we were using BigDecimal to perform some calculations when printing the Quarkus startup time.
D’oh.
We replaced that code, only to discover another issue:
BigDecimal was also being eagerly initialized in Hibernate ORM for a very narrow use case in the DurationJavaType class.
That has since been fixed as well.
|
Just like with This is about avoiding the cost when you don’t actually need it. |
Time zones
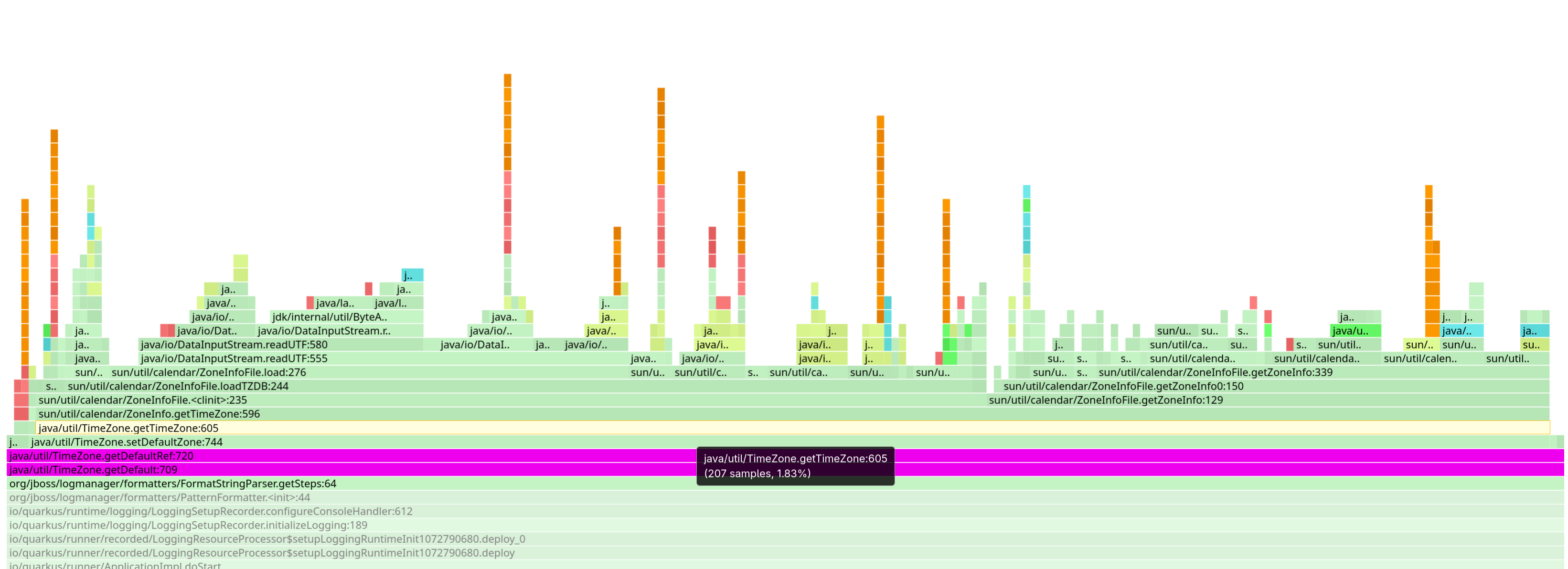
We all know time zones are hard. But now we also know that loading them is slow.
The time zone database is quite large, and loading it, for example when calling TimeZone.getDefault(), can take a noticeable amount of time.
Who would need a time zone in a server application, right? For instance, your logging layer, which wants to print timestamps in the local time zone.
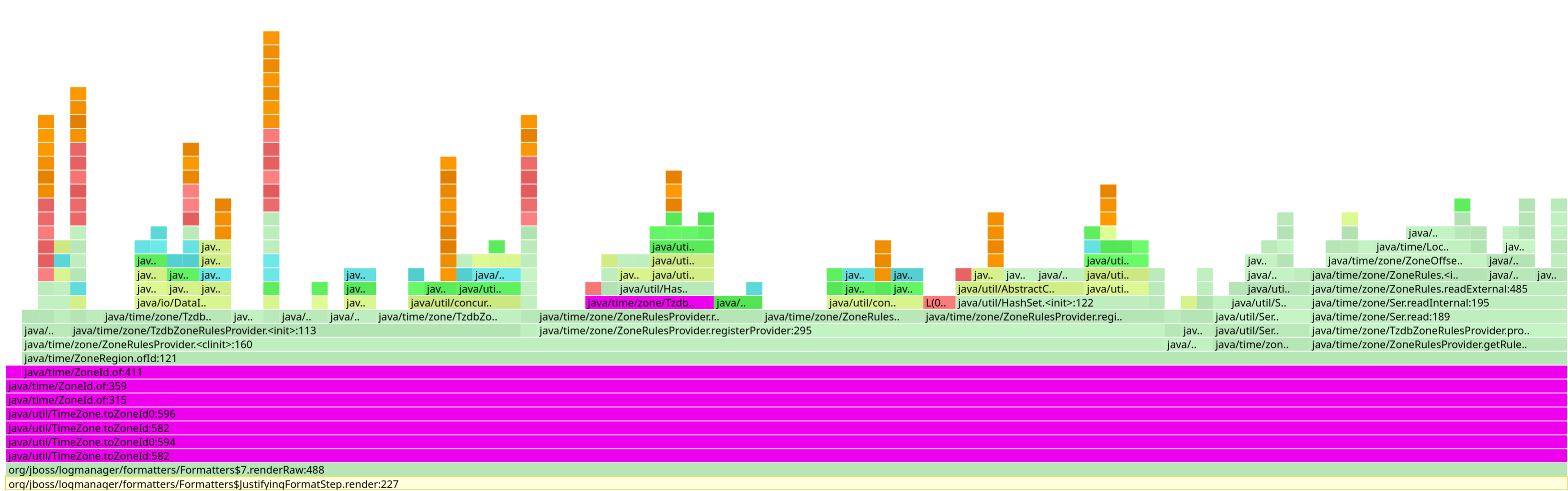
And what’s also interesting is that there’s an additional cost for transforming the time zone to a ZoneId, as you also have to load the zone rules.
These two issues still exist and I have no idea if we can even solve them, but we were able to mitigate their cost somewhat in Quarkus when using the specific packaging we developed for AOT.
Conclusion
This post is about the work we did in Quarkus and the libraries Quarkus relies on. But I would argue that the lessons we learned are applicable across the entire Java ecosystem.
I hope that by sharing our experience, we can inspire other projects, especially library and framework authors, to take a similar approach and improve their startup performance.
And to be honest, this isn’t just about improving startup performance, it’s also about reducing the resources wasted during startup. We often talk about Green IT; let’s make our libraries and frameworks greener, especially in cases where it’s simple to achieve.
We’ve shared some of our findings and recipes, but I’m sure there are others that are specific to each library and framework. Now is a great time to look at your own startup profiles and see if you can spot some low-hanging fruit to boost performance. And with Quarkus 3.32 and our new AOT integration coming soon, this is going to be easier than ever.
If you have questions, you know where to find us, and if you find something interesting, please share it with us, we’d love to hear about it!
Onwards!
Come Join Us
We value your feedback a lot so please report bugs, ask for improvements… Let’s build something great together!
If you are a Quarkus user or just curious, don’t be shy and join our welcoming community:
-
provide feedback on GitHub;
-
craft some code and push a PR;
-
discuss with us on Zulip and on the mailing list;
-
ask your questions on Stack Overflow.