How to implement Kafka Serializers and Deserializers?

When your application writes a record into a Kafka topic or when it consumes a record from a Kafka topic, a mechanism of serialization and deserialization happens. The serialization process transforms the business objects you want to send to Kafka into bytes. The deserialization process is the opposite. It receives the bytes from Kafka and recreates the business objects.
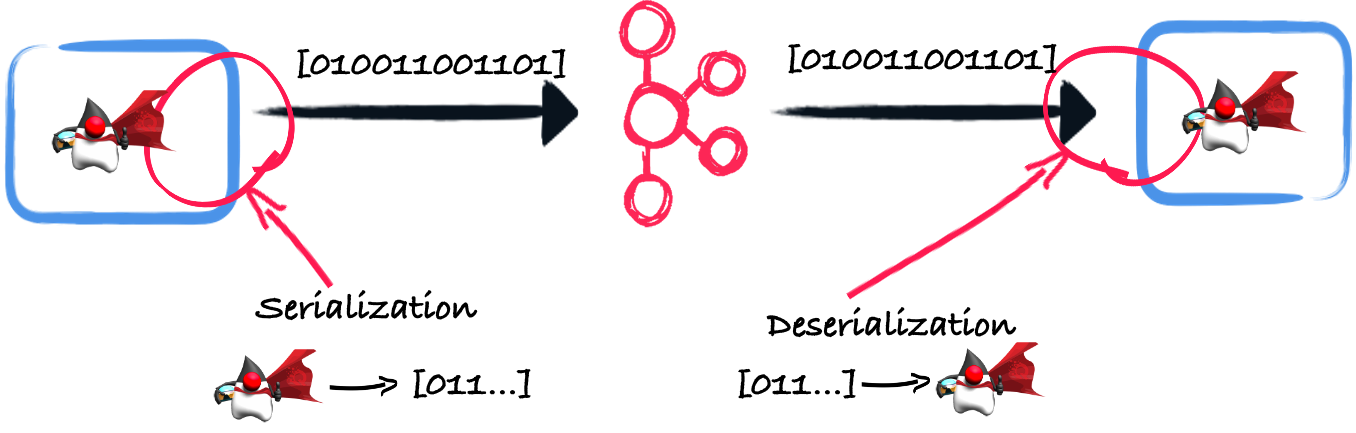
This blog post explores different approaches for this serialization and deserialization and explains how you can implement a custom serializer and deserializer. It also highlights facilities provided by the Kafka connector from Quarkus.
Why do I need a custom serializer and deserializer?
Kafka provides a set of serializers and deserializers for the common types: String, Double, Integer, Bytes…
But that’s rarely enough for business objects, even for objects are simple as:
package me.escoffier.quarkus;
public record Hero(String name, String picture) {
}Fortunately, Kafka lets us implement our own. To achieve this, you need to implement the following interfaces:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) { }
byte[] serialize(String topic, T data);
default byte[] serialize(String topic, Headers headers, T data) {
return serialize(topic, data);
}
@Override
default void close() { }
}public interface Deserializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) { }
T deserialize(String topic, byte[] data);
default T deserialize(String topic, Headers headers, byte[] data) {
return deserialize(topic, data);
}
@Override
default void close() { }Once implemented, you need to configure your Kafka producer and consumer’s key and value serializer and deserializer. If you are using the Kafka connector from Quarkus, it will look like this:
mp.messaging.incoming.heroes.value.deserializer=me.escoffier.MyHeroDeserializer
mp.messaging.outgoing.heroes.value.serializer=me.escoffier.MyHeroSerializerBut, no worries, Quarkus has a few magic tricks for you.
In the rest of this post, we will use the following application:
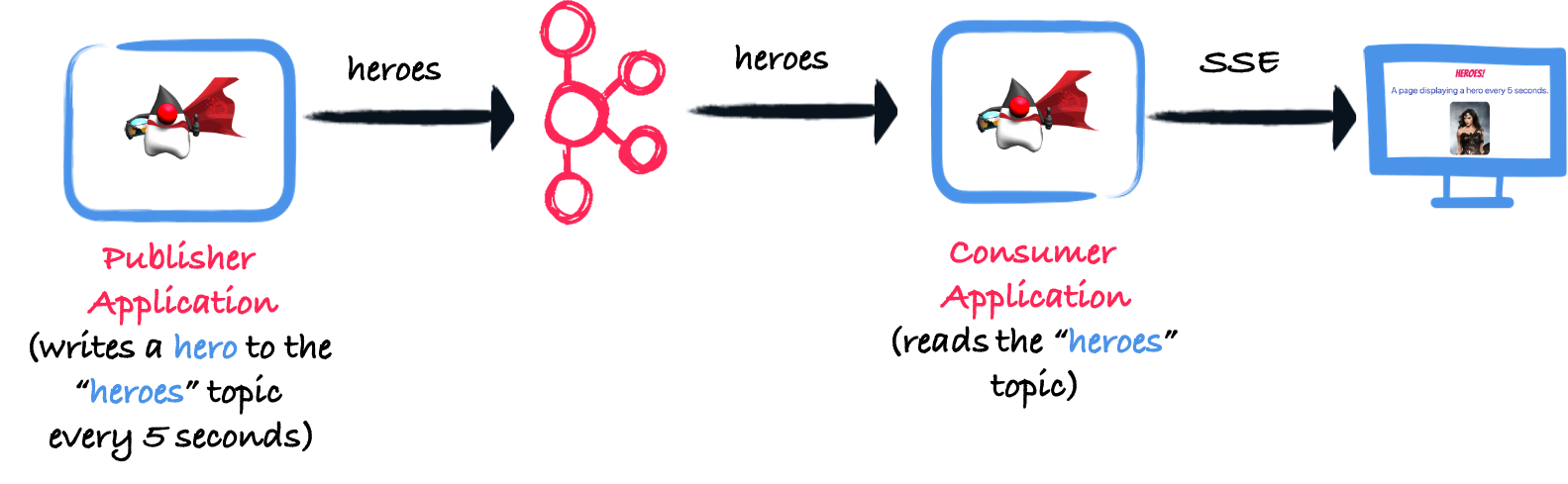
The code can be found on https://github.com/cescoffier/quarkus-kafka-serde-demo. We will develop three variants:
-
The first version uses JSON.
-
The second version uses Avro.
-
The third version uses custom (and dumb) serializer and deserializer.
Using JSON
Using JSON with Kafka is very popular. As most web applications use JSON to exchange messages, using it with Kafka sounds like a natural extension.
In our case, it means transforming the instances of Hero to a JSON document and then using the String serializer. For the deserialization process, we would do the reverse process. To do that with Quarkus, you have nothing to do: Quarkus generates the custom JSON serializer and deserializer for you.
In the json-serde directory, you can find a version of the application using JSON to serialize and deserialize the records. It does not contain any custom code or configuration. Quarkus automatically detects that you need to write and consume Heroes and generates the serializer and deserializer for you. It also configures the channels for you. Of course, you can override the configuration, but it’s what you want most of the time.
To run this application, open two terminals.
In the first one, navigate to json-serde/json-serde-publisher, and run mvn quarkus:dev.
In the second terminal, navigate to json-serde/json-serde-consumer, and run mvn quarkus:dev.
Then, open a browser to http://localhost:8080.
Every 5 seconds, a new picture of a hero is displayed.

Using Avro
The second approach uses Avro. Avro has several advantages over (bare) JSON:
-
It’s a binary and compact protocol. The payloads will be a lot smaller than with JSON.
-
The serialization and deserialization processes are a lot faster (avoiding reflection).
-
The format of the message is defined using a schema stored on a schema registry which enables versioning and enforces the structure.
The last point is essential. To use Avro, you need a schema registry. In this post, we are using Apicurio, but you can use the Confluent Schema Registry or Karapace. Quarkus provides a dev service for Apicurio, so you have nothing to do (as soon as you can run containers on your machine).
To use Avro, we need a schema. In hero.avsc, you can find the schema representing our heroes:
{
"namespace": "me.escoffier.quarkus.avro",
"type": "record",
"name": "Hero",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "picture",
"type": "string"
}
]
}Avro relies on code generation. It processes the schema to generate Java classes with the defined fields and serialization and deserialization methods.
While in general, using code generation is an extra step, with Quarkus, it’s built-in!
Once you have a schema in src/main/avro, it generates the code for you, and you are ready to use the produced classes.
In AvroPublisherApp and AvroConsumerResource, we are using the Hero class generated from the schema.
As an example, the consumer application looks like this:
package me.escoffier.quarkus;
import io.smallrye.mutiny.Multi;
import me.escoffier.quarkus.avro.Hero; // Generated class
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.jboss.resteasy.reactive.RestStreamElementType;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
@Path("/heroes")
public class AvroConsumerResource {
@Channel("heroes")
Multi<Hero> heroes; // The hero class is generated from the schema.
@GET
@Produces(MediaType.SERVER_SENT_EVENTS)
@RestStreamElementType(MediaType.APPLICATION_JSON)
public Multi<Hero> stream() {
return heroes;
}
}Quarkus automatically finds the serializer and deserializer and configures the channels, so again: no config. However, you still need to instruct Apicurio to register the schema. In general, it’s a manual operation, but for development, you can use the following property:
kafka.apicurio.registry.auto-register=trueTo run this application, open two terminals.
In the first one, navigate to avro-serde/avro-serde-publisher, and run mvn quarkus:dev.
In the second terminal, navigate to avro-serde/avro-serde-consumer, and run mvn quarkus:dev.
Then, open a browser to http://localhost:8080.
As for the JSON variant, every 5 seconds, a new picture of a hero is displayed.
This time the Kafka records are serialized using Avro
Writing a custom serializer and deserializer
Of course, you can still write your custom serializer and deserializer.
As mentioned above, you need to implement the Serializer and Deserializer interfaces.
For example, the HeroSerializer class contains a straightforward (and inefficient) approach to serializing our heroes:
package me.escoffier.quarkus.json.publisher;
import org.apache.kafka.common.serialization.Serializer;
import java.nio.charset.StandardCharsets;
public class HeroSerializer implements Serializer<Hero> {
@Override
public byte[] serialize(String topic, Hero data) {
return (data.name() + "," + data.picture())
.getBytes(StandardCharsets.UTF_8);
}
}The HeroDeserializer class contains the deserialization counterpart.
As before, Quarkus discovers these implementations and configures the channels for you. So you do not have to configure anything.
Custom serializers and deserializers can receive configuration attributes.
They receive the producer/consumer configuration in the configure method.
| Custom serializers and deserializers cannot be CDI beans. Kafka instantiates them directly using reflection. |
Conclusion
This post explores different possibilities to serialize and deserialize your messages with Kafka and how Quarkus reduces the amount of boilerplate and configuration you need to use.
So, what should you use?
-
JSON is massively used, but the lack of structure verification, by default, can quickly be a problem if the format evolves rapidly.
-
Avro provides better performances and handles validation and evolutions. But it requires a schema registry. If your system exchanges lots of messages with evolving structures, Avro should be preferred. Also, Avro produces smaller payloads.
-
If you have stringent requirements not covered by the JSON and Avro approaches, you can develop a custom serializer and deserializer.
Note that JSON can be combined with JSON-Schema (with the schema stored on a schema registry). Protobuf is also a possible alternative if you prefer a binary format.