Crafting a Local RAG application with Quarkus

This blog post demonstrate how to build an AI-infused chatbot application using Quarkus, LangChain4j, Infinispan, and the Granite LLM. In this post, we will create an entirely local solution, eliminating the need for any cloud services, including the LLM.
Our chatbot leverages the Granite LLM, a language model that generates contextually relevant text based on user prompts. To run Granite locally, we’ll be utilizing InstructLab, though Podman AI Lab is another viable option.
The core of our application is based on the RAG (Retrieval-Augmented Generation) pattern. This approach enhances the chatbot’s responses by retrieving pertinent information from a vector database — in this case, Infinispan — before generating a response.
Architecture
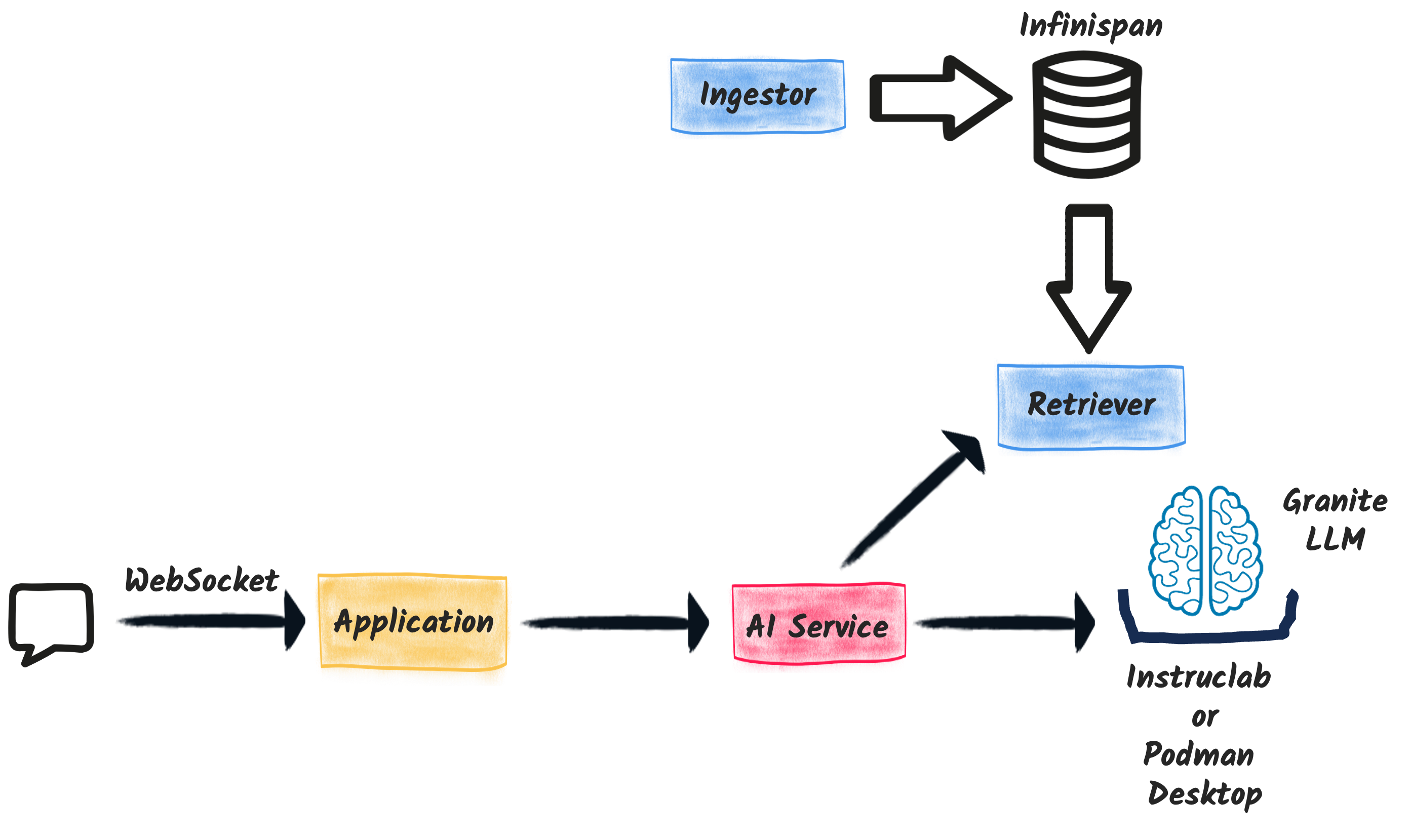
Our chatbot application is composed of four main components:
-
Web Socket Endpoint: This component serves as the communication bridge between the chatbot’s backend and the frontend interface. This component uses the new Quarkus WebSocket-Next extension to handle WebSocket connections efficiently. It relies on the AI Service to interact with the LLM.
-
Ingestor: The ingestor is responsible for populating the database with relevant data. It processes a set of local documents, split them into text segments, compute their vector representation and store them into Infinispan.
-
Retriever: The retriever allows finding relevant text segments into Infinispan. When a user inputs a query, the retriever searches the vector database to find the most relevant pieces of information.
-
AI Service: This is the core component of the chatbot, combining the capabilities of the retriever and the Granite LLM. The AI service takes the relevant information fetched by the retriever and uses the Granite LLM to generate the appropriate responses.
The following picture illustrates the high-level architecture:
A simple explanation of the RAG pattern
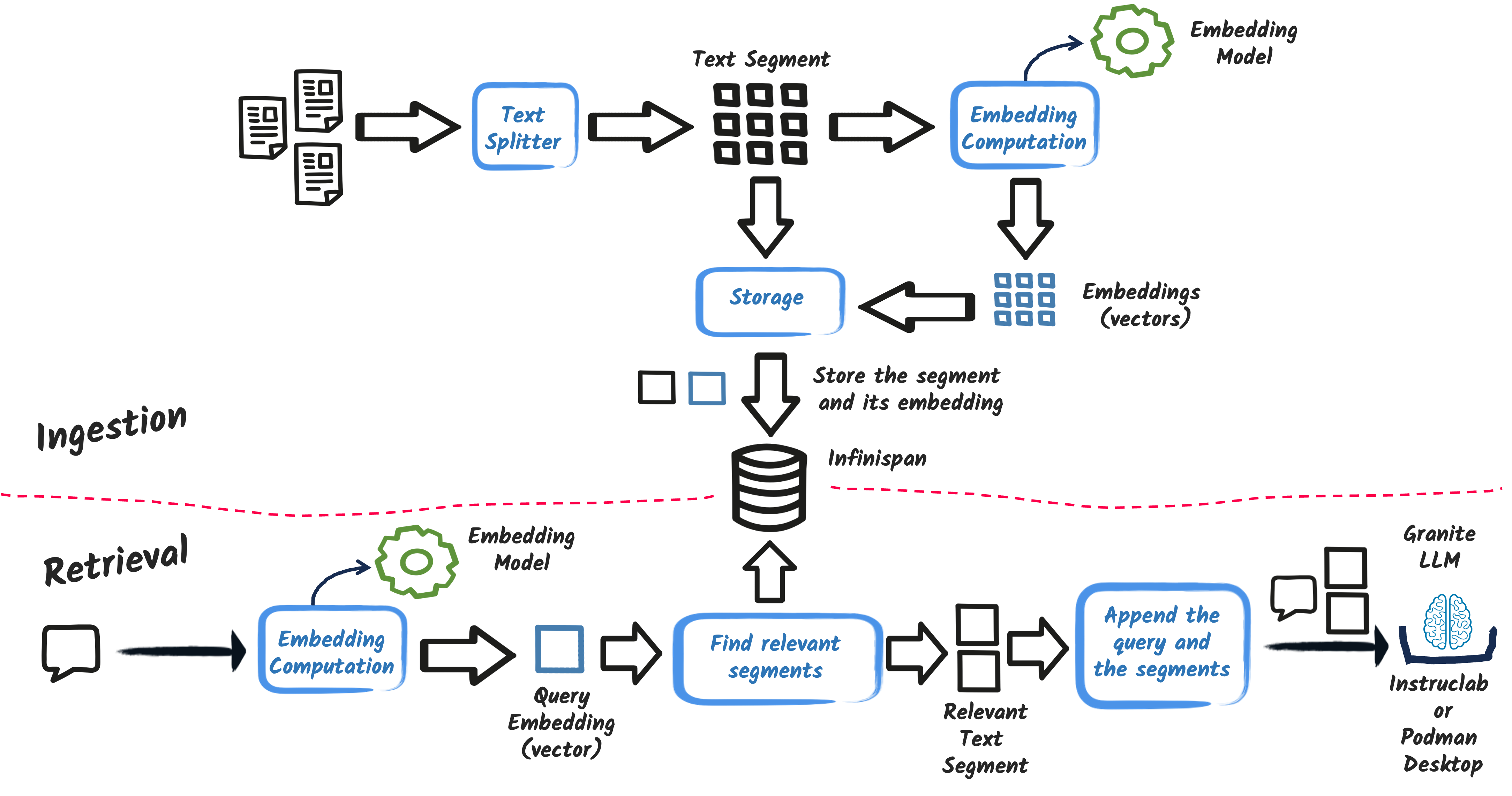
The RAG (Retrieval-Augmented Generation) pattern is one of the most popular AI patterns, combining a retrieval mechanism with a generation mechanism to provide more accurate and relevant responses.
The RAG pattern operates in two main steps:
-
Ingestion: The application ingests a set of documents, processes them, and stores them in a vector database.
-
Retrieval: When a user inputs a query, the application retrieves the most relevant information from the vector database.
The following image gives a high-level overview of the traditional RAG pattern:
There are more advanced version of the RAG pattern, but let’s stick to the basics for this application.
Ingestion
Let’s first look at the ingestion step. The ingestion process involves reading a set of documents, splitting them into text segments, computing their vector representations, and storing them in Infinispan.
The secret of an effective RAG implementation lies in how the text segments are computed.
In our application, we will follow a straightforward approach, but more advanced techniques are available and often required.
Depending on the document, you can use a variety of techniques to split the text into segments, such as paragraph splitting, sentence splitting, or more advanced techniques like the recursive splitter.
Also, if the document has a specific structure, you can use this structure to split the text into segments (like sections, chapters, etc.).
The embedding model is responsible for converting text into a vector representation.
For simplicity, we use an in-process embedding model (BGE-small).
Other options, like the Universal Angle Embedding, are available, but we’ll stick with BGE-small for simplicity.
Retrieval
The second step is the retrieval process. When a user inputs a query, the application searches the vector database to find the most relevant text segments.
To achieve this, the application computes the vector representation of the user query using the same embedding model and compares it with the vector representations of the stored text segments in Infinispan. It selects the most relevant text segments based on the similarity between the query vector and the text segment vectors.
Then, it augments the user query with the retrieved text segments and sends it to the LLM. Note that until this step, the LLM is not used.
Implementing the chatbot
Enough theory—let’s dive into the implementation. You can find the final version on GitHub.
Used extensions and dependencies
To implement our chatbot, we rely on the following Quarkus extensions:
-
quarkus-langchain4j-openai: Integrates LLM providers using the OpenAI API, suitable for both InstructLab and Podman AI Lab. -
quarkus-websockets-next: Provides support for WebSocket communication. -
quarkus-langchain4j-infinispan: Integrates Infinispan with LangChain4j, allowing us to store and retrieve vector representations of text segments. -
quarkus-web-bundler: Bundles frontend resources with the Quarkus application.
We also need a specific dependency to use the BGE-small embedding model:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-bge-small-en-q</artifactId>
</dependency>Configuration
We need a bit of configuration to ensure our application uses Granite and sets up the Infinispan database correctly:
# Configure the Infinispan vectors:
quarkus.langchain4j.infinispan.dimension=384 (1)
# Configure the OpenAI service to use instruct lab:
quarkus.langchain4j.openai.base-url=http://localhost:8000/v1 (2)
quarkus.langchain4j.openai.timeout=60s
quarkus.langchain4j.embedding-model.provider=dev.langchain4j.model.embedding.BgeSmallEnQuantizedEmbeddingModel (3)| 1 | Configure the dimension of the vectors stored in Infinispan, which depends on the embedding model (BGE-small in our case). |
| 2 | Configure the OpenAI service to use InstructLab. You can replace the base URL with the one for Podman AI Lab if you prefer. Indeed, InstructLab and Podman AI Lab expose an OpenAI-compatible API. |
| 3 | Set the default embedding model to BGE-small. |
The Ingestor
With the configuration in place, let’s implement the ingestion part (Ingestion.java).
The ingestor reads documents from the documents directory, splits them into text segments, computes their vector representations, and stores them in Infinispan:
@Singleton
@Startup (1)
public class Ingestion {
public Ingestion(EmbeddingStore<TextSegment> store, EmbeddingModel embedding) { (2)
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.embeddingModel(embedding)
.documentSplitter(recursive(1024, 0)) (3)
.build();
Path dir = Path.of("documents");
List<Document> documents = FileSystemDocumentLoader.loadDocuments(dir);
Log.info("Ingesting " + documents.size() + " documents");
ingestor.ingest(documents);
Log.info("Document ingested");
}
}| 1 | The @Startup annotation ensures that the ingestion process starts when the application launches. |
| 2 | The Ingestion class uses an (automatically injected) EmbeddingStore<TextSegment> (Infinispan) and an EmbeddingModel (BGE-small). |
| 3 | We use a simple document splitter (recursive(1024, 0)) to split the documents into text segments.
More advanced techniques may be used to improve the accuracy of the RAG model. |
The retriever
Next, let’s implement the retriever (Retriever.java). The retriever finds the most relevant text segments in Infinispan based on the user query:
@Singleton
public class Retriever implements Supplier<RetrievalAugmentor> {
private final DefaultRetrievalAugmentor augmentor;
Retriever(EmbeddingStore<TextSegment> store, EmbeddingModel model) {
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(model)
.embeddingStore(store)
.maxResults(2) // Large segments
.build();
augmentor = DefaultRetrievalAugmentor
.builder()
.contentRetriever(contentRetriever)
.build();
}
@Override
public RetrievalAugmentor get() {
return augmentor;
}
}To implement a retriever, expose a bean that implements the Supplier<RetrievalAugmentor> interface.
The Retriever class uses EmbeddingStore<TextSegment> (Infinispan) and EmbeddingModel (BGE-small) to build the retriever.
The maxResults method in the EmbeddingStoreContentRetriever builder specifies the number of text segments to retrieve.
Since our segments are large, we retrieve only two segments.
The AI Service
The AI Service (ChatBot.java) is the core component of our chatbot, combining the capabilities of the retriever and the Granite LLM to generate appropriate responses.
With Quarkus, implementing an AI service is straightforward:
@RegisterAiService(retrievalAugmentor = Retriever.class) (1)
@SystemMessage("You are Mona, a chatbot answering question about a museum. Be polite, concise and helpful.") (2)
@SessionScoped (3)
public interface ChatBot {
String chat(String question); (4)
}| 1 | The @RegisterAiService annotation specifies the retrieval augmentor to use, which in our case is the Retriever bean defined earlier. |
| 2 | The @SystemMessage annotation provides the main instructions for the AI model. |
| 3 | The @SessionScoped annotation ensures that the AI service is stateful, maintaining context between user interactions for more engaging conversations. |
| 4 | The ChatBot interface defines a single method, chat, which takes a user question as input and returns the chatbot’s response. |
The WebSocket endpoint
The final piece is the WebSocket endpoint (ChatWebSocket.java), which serves as the communication bridge between the chatbot’s backend and the frontend interface:
@WebSocket(path = "/chat") (1)
public class ChatWebSocket {
@Inject ChatBot bot; // Inject the AI service
@OnOpen (2)
String welcome() {
return "Welcome, my name is Mona, how can I help you today?";
}
@OnTextMessage (3)
String onMessage(String message) {
return bot.chat(message);
}
}| 1 | The @WebSocket annotation specifies the WebSocket path. |
| 2 | The @OnOpen method sends a welcome message when a user connects to the WebSocket. |
| 3 | The @OnTextMessage method processes the user’s messages and returns the chatbot’s responses, using the injected AI service. |
That’s it! Our chatbot is now ready to chat with users, providing contextually relevant responses based on the RAG pattern.
Running the application
Let’s run the application and see our chatbot in action. First, clone the repository and run the following command:
./mvnw quarkus:devThis command starts the Quarkus application in development mode. Ensure you have InstructLab or Podman AI Lab running to use the Granite LLM. You will also need Docker or Podman to automatically start Infinispan.
|
Podman AI Lab or InstructLab?
You can use either Podman AI Lab or InstructLab to run the Granite LLM locally. Depending on the OS, Podman may not have GPU support. Thus, response time can be high. In this case, InstructLab is the preferred option for better response times. Typically, on a Mac, you would use InstructLab, while on Linux, Podman AI Lab shows great performances. |
Once the application is up and running, open your browser and navigate to http://localhost:8080. You should see the chatbot interface, where you can start chatting with Mona:

Summary
That’s it! With just a few lines of code, we have implemented a chatbot using the RAG pattern, combining the capabilities of the Granite LLM, Infinispan, and Quarkus. This application runs entirely locally, eliminating the need for any cloud services and addressing privacy concerns.
This is just an example of what you can achieve with the Quarkus LangChain4j extension. You can easily extend this application by adding more advanced features, such as sophisticated document splitters, embedding models, or retrieval mechanisms. Quarkus LangChain4J also provides support for advanced RAG, many other LLM and embedding models and vector stores. Find out more on Quarkus LangChain4J.