Frozen RAG (Retrieval-Augmented Generation)
Integrate RAG to anchor Large Language Model (LLM) responses in your enterprise data, with Quarkus handling ingestion pipelines, query execution, embedding generation, context retrieval, and seamless LLM interaction. This blueprint focuses on the foundational RAG pattern (also called frozen RAG); more advanced contextual RAG variants, including multi-source routing and reranking, are covered separately.
Main Use-Cases
- Reduced Hallucinations: RAG ensures that LLM answers are explicitly tied to enterprise-specific sources such as policies, manuals, or knowledge bases. This grounding reduces the risk of fabricated or misleading responses and increases trust in AI-assisted decision-making.
- Up-to-Date Information: Because the retrieval step pulls directly from current document repositories and databases, responses adapt automatically as content evolves. There is no need to retrain or fine-tune the underlying model whenever business data changes.
- Cost Efficiency: By retrieving only the most relevant context chunks, prompts stay concise. This reduces token usage in LLM calls, which directly lowers cost while preserving accuracy and completeness.
- Java-Native Enterprise Integration: Quarkus provides a first-class runtime for embedding RAG workflows into existing enterprise systems. Developers can secure RAG services with OIDC or LDAP, expose them through familiar REST or Kafka APIs, and monitor them with Prometheus and OpenTelemetry. Because RAG runs inside the same application fabric as other Java services, it fits naturally into existing authentication, authorization, deployment, and observability workflows. This ensures AI augmentation is not just added, but part of the enterprise architecture.
Architecture Overview
Contextual RAG focuses on integrating Retrieval-Augmented Generation (RAG) to ground Large Language Model (LLM) responses in organizational data.
The architecture is divided into two main phases:
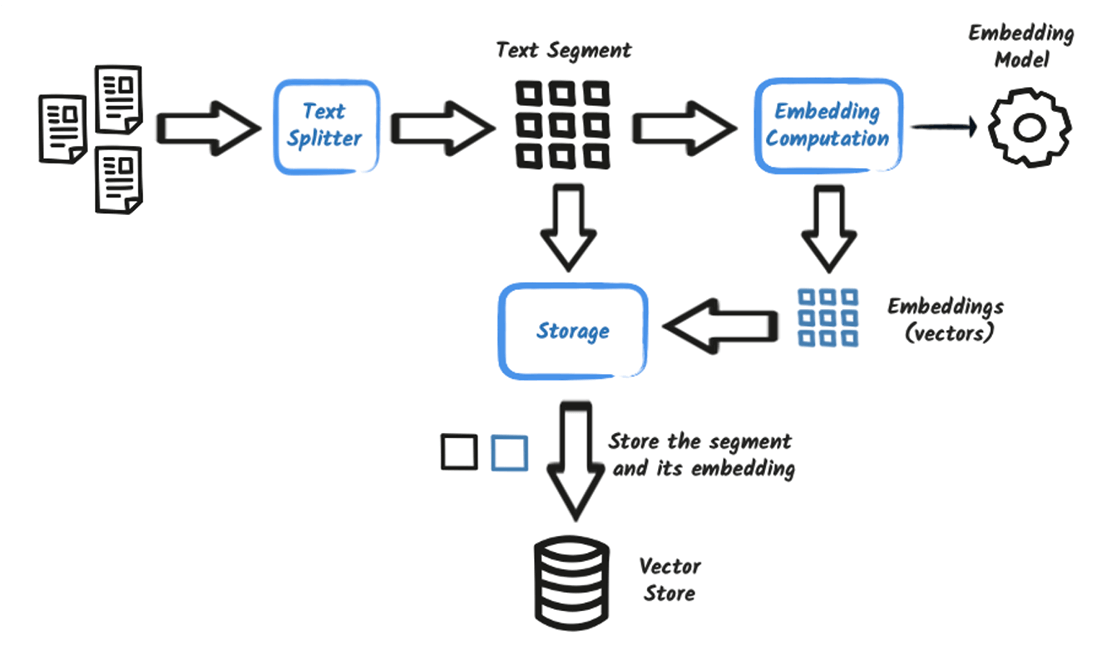
Ingestion: This phase prepares enterprise knowledge for retrieval. In a frozen RAG setup, data typically originates from unstructured document sources such as manuals, PDFs, or reports.
- Documents are processed by a "Text Splitter" to break them into smaller chunks.
- These chunks are then converted into numerical representations (embeddings) using an "Embedding Model".
- The embeddings are stored in a "Vector Store" for semantic similarity searches.
- Metadata about the documents, such as lineage and other relevant information, is stored in a "Metadata Store".
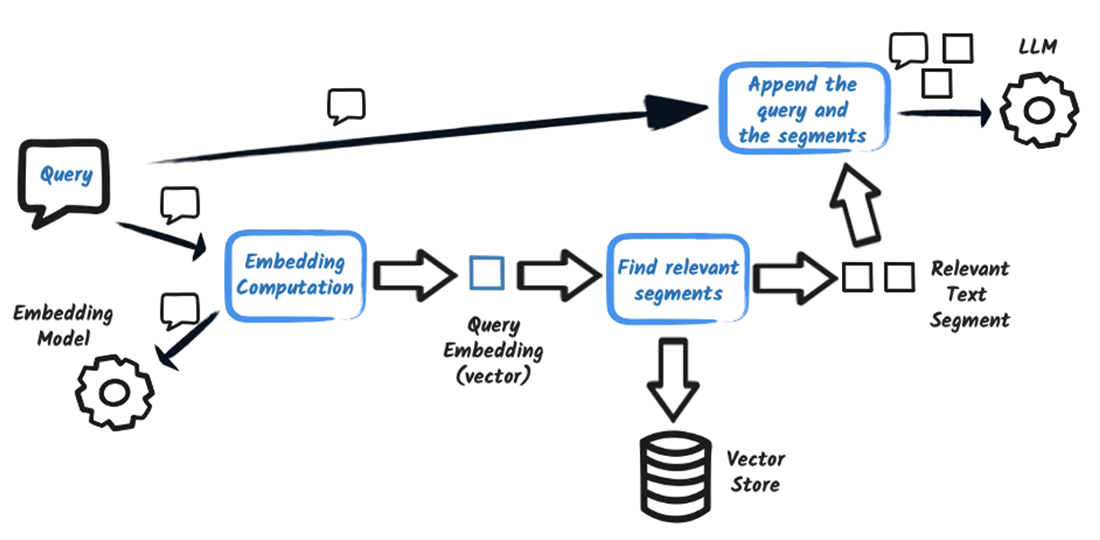
Query: This phase handles user queries and generates grounded answers.
- A "User Query" is received and processed by a "Query Embedding" component to create an embedding of the query.
- The query embedding is used in a "Similarity Search" against the "Vector Store" to retrieve relevant document chunks. The "Vector Store" "serves" the similarity search.
- The retrieved chunks, along with metadata from the "Metadata Store" (which acts as the "source of truth"), are assembled into a "Context Pack".
- The "Context Pack" is used by a "Prompt Assembly" component to construct an "Enhanced Prompt" that includes the relevant context.
- The "Enhanced Prompt" is fed into an "LLM (LangChain4j)".
- The LLM generates a "Grounded Answer" based on the provided context.
This two-phase approach allows for reduced hallucinations in LLM responses, up-to-date information without retraining, cost efficiency by retrieving only relevant information, and seamless integration with existing enterprise Java services and workflows.