Contextual RAG (Multi-Sources, Rerank, Injection)
Advanced Contextual RAG extends the core frozen RAG pattern by incorporating multi-source retrieval, reranking, and content injection techniques. This is designed for more complex enterprise scenarios where information might be spread across various systems, requiring more sophisticated methods to ensure accuracy, relevance, and explainability. It allows for dynamic information handling, complex query processing, and provides clearer lineage for auditable decisions, making it ideal for high-stakes applications.
Main Use-Cases
- Complex Queries: Addresses intricate questions requiring synthesis from multiple sources.
- Dynamic Information: Handles rapidly changing data environments by incorporating real-time updates.
- High-Accuracy Needs: Reranking and injection ensure more precise and relevant answers.
- Auditable Decisions: Provides clear lineage and context for generated responses, crucial for compliance and debugging.
Architecture Overview
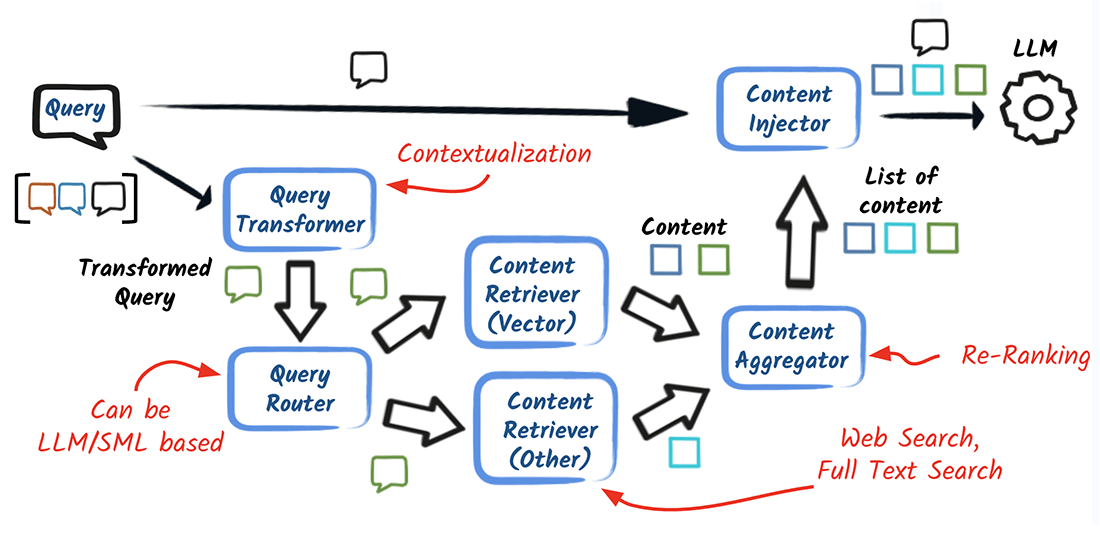
The process begins with a User Query, which is first processed by a Query Transformer to refine or enhance it for more effective retrieval. The transformed query is then passed to a Query Router that decides which knowledge sources to target. For unstructured data, the ingestion pipeline remains the same as in the foundational RAG architecture (documents split, embedded, and stored in a vector store), but contextual RAG extends retrieval to multiple sources such as structured databases, APIs, and search indexes.
The Query Router is responsible for directing the query to multiple retrieval sources simultaneously. These sources include:
- Vector Retriever: Retrieves information based on semantic similarity from a vector store.
- Web/Search Retriever: Gathers information from the web or external search engines.
- Database Retriever: Extracts relevant data from structured databases.
- Full-Text Retriever: Performs keyword-based searches across a corpus of documents.
All the information retrieved from these diverse sources is then fed into an Aggregator/Reranker. This component combines and prioritizes the retrieved content based on relevance to the original query.
The aggregated and reranked content is passed to a Content Injector (Prompt Builder). This component constructs an Enhanced Prompt for the Large Language Model (LLM) by incorporating the retrieved context alongside the original user query.
Finally, the LLM processes the Augmented Prompt, using the provided context to generate an answer. Alongside the answer, the system can return the retrieved source segments for transparency and verification, though these should be considered supporting context rather than strict citations.
Scalability & Performance
Efficiently scaling and optimizing the performance of your AI solutions are crucial for enterprise adoption and operational success. While this blueprint only gives you some high level guidance, we strongly recommend to also look into the non functional aspects of your solution and ways to address these concepts:
- Domain/Tenant Sharding: Retrieves information based on semantic similarity from a vector store.
- Caching: Cache query vectors and top-K hits for improved performance.
- Asynchronous Ingestion: Utilize asynchronous ingestion to batch embeddings and stream deltas.
- Lean Prompts: Prioritize token budget for context, keeping prompts concise.
Security
Architecting secure enterprise AI solutions demands a proactive approach to safeguard sensitive data and preserve organizational integrity. Below are some first thoughts about critical security considerations and architectural patterns you should further investigate when building your solution.
- Authorization at retrieval: Before injecting context, filter by user/tenant claims.
- Audit lineage: Store the chunk→document→source linkage with timestamps.
- PII controls: Redact or mask sensitive spans before embedding and prompting.
- Guard responses: Post-filter for data leakage and policy violations.